![[Floris Lambrechts]](../../common/images/Floris_Lambrechts.png)
por Floris Lambrechts
<floris(at)linuxfocus.org>
Sobre el autor:
Durante años he sido eI editor de LinuxFocus en los Países
Bajos. Estoy estudiando ingeniería industrial por la rama de electrónica
en Lovaina, Bélgica, y "pierdo" el tiempo enredando en Linux, PHP,
XML y LinuxFocus, a la vez que leo libros como los de Stephen Hawking y
(en este momento) The Humane Interface, de Jef Raskin.
Taducido al español por:
Javier Fdez. Retenaga <inignaga(at)teleline.es>
Contenidos:
|
Empezando a conocer el XML
![[Illustration: xml]](../../common/images/illustration242.png)
Resumen:
Esta es una bastante breve introducción al XML. Conocerá
a Micifú el meta-gato, las normas sintácticas del XML y algunos
DTDs. No se preocupe, nos explicaremos ;-)
_________________ _________________ _________________
|
Introducción
En el verano de 2001, algunos de los editores de LF nos juntamos en Burdeos
durante el LSM. Muchas conversaciones
y discusiones del grupo del LSM particularmente interesado en la documentación
resultaron girar en torno al mismo asunto: el XML. Se dedicó largas
(y entretenidas) horas a explicar qué es exactamente el XML, para
qué es bueno y cómo puede utilizarse. Si está interesado,
eso es precisamente lo que este artículo tratará de discutir.
Quisiera dar las gracias a Egon Willighagen y a Jaime Villate por introducirme
al XML. Este artículo se basa de alguna manera en la información
contenida en los artículos de Jaime, que puede encontrar más
abajo en los enlaces.
Qué es el XML
Todos los que nos ocupamos de la documentación sabíamos,
más o menos, de qué iba el XML. A fin de cuentas, su sintaxis
es muy similar a la del HTML y no es más que otro lenguaje de marcas,
como el SGML y (de nuevo) el HTML, ¿no es eso? Así es. Pero
hay más.
El XML tiene algunas propiedades que hacen de él un formato
de datos útil para casi todo. Parece que pueda describir las cosas
más complejas y continuar siendo fácil de leer para los humanos
y fácil de analizar por los programas. ¿Cómo puede
ser eso? Investiguemos este curioso lenguaje.
Micifú, el meta-gato
Antes que nada, el XML es un lenguaje de marcas. Los documentos
escritos en un lenguaje de marcas contienen básicamente dos
cosas: datos y metadatos. Si usted sabe qué son exactamente
los datos, por favor hágamelo saber, pero hasta ese momento hablemos
de los metadatos ;). Dicho de una manera sencilla: los metadatos son información
extra que añade un contexto o un sentido a los datos mismos. Un
ejemplo sencillo: tomemos la frase 'Mi gato se llama Micifú'.
Un humano como usted sabe que 'gato' es el nombre de una especie
animal y que 'Micifú' es su nombre propio. Los programas
informáticos, sin embargo, no son humanos y no saben nada de eso.
De ahí que utilicemos los metadatos para añadir un sentido
a los datos (¡con sintaxis XML, por supuesto!):
<frase>
Mi <animal>gato</animal> se llama
<nombre>Micifú</nombre>.
</frase>
Ahora un programa informático por tonto que sea puede decir que
'gato' es una especie y que 'Micifú' es un nombre. Si queremos producir
un documento en el que todos los nombres se impriman en azul
y todas las especies en rojo, el XML nos lo
pone muy fácil. Sólo por el gusto de hacerlo, esto es lo
que obtendríamos:
Mi gato se llama Micifú.
Ahora, teóricamente, podemos poner toda la información
relativa al diseño (los colores, en este caso) en un archivo aparte,
en una así llamada hoja de estilo. Cuando hacemos esto, en realidad
estamos separando la información relativa al diseño del contenido,
lo que algunos consideran el Santo Grial del diseño de páginas
webTM.
Hasta aquí no hemos hecho nada de especial: añadir metadatos
es para lo que están diseñados los lenguajes de marcas. Entonces,
¿qué hace tan especial al XML?
La policía sintáctica
Ante todo, el XML tiene una sintaxis muy estricta. Por ejemplo, en XML
cada <etiqueta> ha de tener una </etiqueta>
de cierre. [Nota: puesto que es un poco tonto escribir <etiqueta></etiqueta>
cuando no hay nada en medio, puede también escribir <etiqueta
/> y ahorrarse quizás un par de minutos de su vida].
Otra regla es que no puede 'mezclar' etiquetas. Tiene que cerrar las
etiquetas en el orden inverso al que las abrió. Algo como lo siguiente
no es válido:
<B> Texto en negrilla <I>Texto en negrilla
y cursiva </B> Texto en cursiva </I>
Las reglas sintácticas dicen que ha de cerrar la etiqueta </I>
antes de cerrar </B>
Y, esté atento, todos los elementos de un documento XML
han de estar contenidos en etiquetas (salvo, naturalmente, las etiquetas
inicial y final). Esta es la razón de que en el ejemplo de arriba
hayamos escrito las etiquetas <frase>
alrededor de la frase. Sin ellas, algunas de las palabras de la frase no
estarían incluidas entre etiquetas, y eso, como tantas cosas, pone
loca a la policía sintáctica.
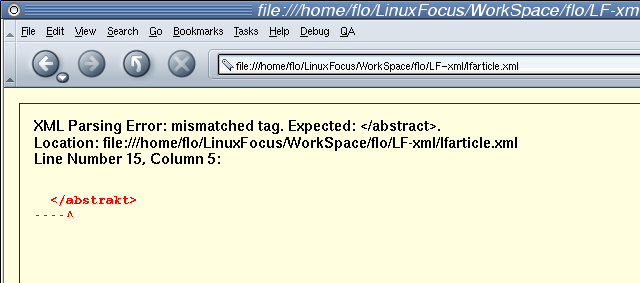
La policía sintáctica de Mozilla en marcha...
Pero una policía fuerte también tiene sus ventajas: procura
orden. Puesto que el XML sigue reglas sintácticas tan estrictas,
es muy fácil de leer por los programas. Además, los datos
de sus documentos en XML están muy estructurados, lo que los hace
fáciles de leer y de escribir para los humanos.
Pero dese cuenta de que las posibilidades 'teóricas' del XML
no siempre son realizables en la práctica. Por ejemplo, los analizadores
sintácticos de XML más habituales están lejos de ser
rápidos, y a menudo son realmente grandes. Parece así que
el XML no es en absoluto fácil de leer por los programas. Digamos
que ciertamente no es una buena idea hacerlo todo en XML, sólo
porque es posible. Para aplicaciones en las que precise hacer muchas búsquedas
en un documento, o cuando se trate de documentos muy grandes, a menudo
el XML no es la elección más acertada. Pero esto no significa
que sea imposible utilizarlo para esos propósitos.
Un buen ejemplo de la potencia del XML, pero también de su lentitud,
es el hecho de que con él puede escribir bases de datos (¡intente
hacerlo en HTML! :p). Eso es exactamente lo que Egon Willighagen ha hecho
para la sección holandesa de LinuxFocus (en un enlace al final de
la página puede encontrar el artículo en que explica el procedimiento
seguido). En este caso se prefirió la flexibilidad y extensibilidad
de un formato artesanal antes que la pura velocidad (digamos, mySQL).
En lo relativo a la estricta sintaxis del XML: si consigue hacer buenas
migas con los verificadores sintácticos, puede haber algunas maneras
de hacer que la policía haga parte de su trabajo. Si quiere que
así sea, tendrá que usar inteligentemente un DTD...
El DTD
En nuestro pequeño ejemplo de antes, 'Micifú el meta-gato',
hemos inventado nuestras propias etiquetas XML. Por supuesto, la policía
no permite actos creativos así. Los 'hombres de azul' quieren saber
qué está usted haciendo, cómo y (si es posible) por
qué. Bien, no hay problema, puede explicarlo todo con el DTD...
Un DTD le permite ínventar' nuevas etiquetas. De hecho, le permite
inventar lenguajes completamente nuevos, simpre que respeten la sintaxis
del XML.
El DTD (Document Type Definition) es un archivo que contiene
una descripción de un lenguaje XML. Se trata en realidad de un listado
de todas las etiquetas posibles, sus posibles atributos y sus combinaciones
posibles. El DTD describe lo que es posible en su lenguaje XML y lo que
no lo es. Así, cuando hablamos de un 'lenguaje XML' estamos hablando
en realidad de un DTD específico.
Ponga a la policía a trabajar
En ocasiones el DTD lo forzará a hacer algo en un lugar específico.
Por ejemplo, el DTD puede forzarlo a incluir una etiqueta que contenga
el título del documento. Lo bueno de esto es que ya existe software
(p. e., un módulo de emacs) capaz de escribir automáticamente
las etiquetas requeridas.
De ese modo, algunas partes de la estructura de su documento se rellenan
automáticamente. Como la sintaxis es tan estricta y bien definida,
el DTD puede guiarle durante el proceso de escritura de un documento. Y
cuando cometa errores tales como olvidarse de poner una etiqueta al final,
la policía le informará. Así, después de todo
los polis no están tan 'locos'; donde los policías del mundo
real dicen 'Tiene derecho a guardar silencio', la policía del XML
le habla con toda amabilidad de un 'Syntax error @ line xx : '... :)
Y mientras la policía hace todo ese trabajo por usted, por supuesto
usted
puede continuar y centrarse en el contenido.
El mezclado
Una última gran característica del XML es la posibilidad
de utilizar varios DTDs a la vez. Esto significa que puede utilizar a la
vez diferentes tipos de datos en un mismo documento.
Esta 'mezcla' se hace con espacios de nombres xml. Por ejemplo, usted
puede incluir el DTD Docbook en su documento .xml (para el prefijo
'dbk' en este ejemplo).
Todas las etiquetas de Docbook estarán entonces listas para
ser utilizadas en su documento de la siguiente manera. Digamos que hay
una etiqueta de Docbook<una _etiqueta>:
<dbk:una_etiqueta> unas palabras </dbk:una_etiqueta>
Empleando el sistema de espacios de nombres puede utilizar cualquier
etiqueta y cualquier atributo de cualquier DTD xml. Esto le abre un mundo
de posibilidades, como puede ver en el siguiente apartado...
DTDs disponibles
Este es un pequeño conjunto de DTDs que están ya (parcialmente)
en uso.
-
Docbook-XML
Docbook es un lenguaje para escribir documentos estructurados, por
ejemplo, libros y artículos. Pero también se utiliza para
tareas muy diferentes. Docbook es en realidad un DTD de SGML (SGML
es un lenguaje de marcas estándar), pero existe también una
-popular- versión del mismo en XML. Este es uno de los DTDs de XML
más populares.
-
MathML
MathML es el Mathematical Markup Language (Lenguaje de Marcas
Matemático), que se utiliza para describir expresiones y
fórmulas matemáticas. Es una herramienta verdaderamente pulcra
para la gente del mundo de las matemáticas. Los químicos,
por su parte, no tienen por qué estar celosos de sus colegas los
matemáticos; para ellos existe algo como el CML, o Chemical Markup
Language. Fíjese en que Mozilla 1.0 está por defecto
preparado para el MathML.
-
RDF
RDF es el Resource Description Framework (Marco Descriptivo
de Recursos). Está diseñado para ayudar a codificar y reutilizar
metadatos; en la práctica a menudo es utilizado en las páginas
web
para comunicar a otras páginas qué novedades están
exponiendo. Por ejemplo, la página holandesa linuxdot.nl.linux.org
utiliza el archivo RDF de otras páginas para exponer las novedades
de estas. Las páginas de noticias más populares (como, por
ejemplo, Slashdot) tienen un archivo RDF a disposición, de tal forma
que usted puede copiar las cabeceras de las noticias en, por ejemplo, un
marco lateral de su página personal.
-
SOAP
SOAP son las siglas de Simple Object Access Protocol. Es un
lenguaje utilizado por procesos para comunicarse unos con otros (intercambiar
datos y realizar llamadas a procedimientos remotos). Con SOAP, los procesos
pueden comunicarse unos con otros a distancia, por ejemplo mediante un
protocolo http (internet). Creo que Atif, aquí en LF, puede decirle
más acerca de esto; vea los enlaces :-)
-
SVG
Scalable Vector Graphics. Se supone que el trío PNG,
JPEG2000 y SVG englobará el futuro de las imágenes en la
web.
El PNG ocupará el lugar del GIF (mapas de bits con transparencia,
comprimidos sin pérdidas), y el JPEG2000 podría algún
día suceder al .jpg de hoy (mapas de bits con un grado configurable
de compresión con pérdidas). El SVG no es un formato de imágenes
basado en mapas de bits, sino en vectores, lo que significa que las imágenes
no se representan mediante píxeles, sino mediante formas matemáticas
(líneas, cuadrados...). El SVG tiene también funciones para
cosas tales como la escritura y la animación, lo que lo hace comparable
al Flash de Macromedia. Puede emplear JavaScript en los archivos .svg,
y utilizando ese JavaScript puede a su vez escribir código .svg.
Bien flexible, ¿eh?
Pero el svg es relativamente nuevo; por el momento sólo hay
disponible un accesorio de alta calidad de SVG para navegadores (es de
Adobe, para plataformas Windows y Mac). Mozilla está trabajando
en un visor incorporado de SVG, pero todavía no está terminado
y para poder utilizarlo hay que bajarse una versión del navegador
compilada al efecto.
NOTA: Los archivos .svg pueden hacerse bastante grandes, por
lo que a menudo se encontrará con archivos .svgz. Estas son versiones
comprimidas haciendo uso del algoritmo gzip.
-
XHTML
XHTML es la variante XML del HTML version 4.01. Debido a la estricta
sintaxis del XML, hay algún cambio: hay algunas cosas que se pueden
hacer en HTML que no son válidas en XHTML. Pero, por contra, una
página en XHTML es al mismo tiempo una página de HTML válida.
Recuerde que el programa HTML tidy puede convertir sus actuales
páginas HTML en XML.
-
Los otros
Hay otros muchos formatos de archivo nuevos que emplean el XML, a menudo
en combinación con compresiones .gz or .zip. Sólo un ejemplo:
los formatos de archivo de KOffice son DTDs de XML. Esto es muy útil,
pues permite al usuario combinar la funcionalidad de diferentes aplicaciones
dentro de un documento. P. e., usted puede escribir un documento de KWord
con una hoja de cálculo KChart dentro de él.
Enlaces
El W3C, o World Wide Web Consortium
Tienen información sobre XML, MathML, CML, RDF, SVG, SOAP, XHTML,
espacios de nombres...
www.w3.org
Algún material de Jaime Villate:
Introducción
al XML
Creación
de artículos y páginas web usando XML en Linux
LSM-slides
HTML tidy, el programa:
www.w3.org/People/Raggett/tidy
Docbook
www.docbook.org
Proyecto SVG de Mozilla.org
www.mozilla.org/projects/svg
Artículos relevantes de LinuxFocus:
Empleo de XML y XSLT para
desarrollar LinuxFocus.org (/Holanda)
Crear documentos PDF con DocBook
Formulario de "talkback" para este artículo
Cada artículo tiene su propia página de "talkback". A través de esa página puedes enviar un comentario o consultar los comentarios de otros lectores
2002-12-02, generated by lfparser version 2.34