|
|
|
| Este documento está disponible en los siguientes idiomas: English Castellano Deutsch Francais Turkce Polish |
![[Photo of the Author]](../../common/images/RalfWieland.jpg)
por Ralf Wieland <rwieland-at-zalf.de> Sobre el autor: Utilizo Linux (desde 0.88pl12) para programar simulaciones de entorno, redes neuronales y sistemas difusos. Además estoy interesado en la electrónica y el hardware, y también uso Linux en estos campos. Taducido al español por: Roberto Hernando Velasco (homepage) Contenidos: |
Demografía prácticaResumen:
Este artículo se ocupa de la cuestión "¿Cuál será la estructura
de la población dentro de 50 o 100 años, si sigue creciendo
como ahora?" Como parte de mi intento para responder a esta pregunta,
presento un pequeño programa QT, con el que los lectores
pueden experimentar por sí mismos. Algunos podrán
sacarle provecho e incluso puede que algunos desarrollen sus propias
extensiones del programa.
|
La inmigración y la integración de extranjeros en nuestro país es uno de los temas de discusión preferidos por nuestros políticos. Las empresas basan el perfil de sus productos en el crecimiento demográfico. La sanidad, el sistema de pensiones, etc. dependen de cómo evoluciona la población.
Se hacen muchas investigaciones en este tema, publicándose estudios muy profundos. A pesar de ello la mayoría de la gente ignora todo el proceso que está detrás del crecimiento demográfico. Este artículo se ocupa poco de la exactitud política o científica, ocupándose principalmente de nuestra propia experiencia. ¿Por qué no echar un vistazo, incluso de forma divertida, a la población en 50 o 100 años? ¿Qué pasa cuando unos dejan el país, y qué pasa cuando otros llegan? Para permitirnos experimentar con las distintas posibilidades, he desarrollado un pequeño programa QT.
La mayoría de las personas se pregunta alguna vez de dónde vienen realmente las 'pirámides poblacionales' que se ven en los periódicos - ya sabe, esas que muestran, por ejemplo, qué población habrá en 50 años. ¿En qué información se basan esos diagramas?
Si piensa en ello, se dará cuenta de que todo depende del número de niños nacidos, el número de gente que muere, y la tasa de movimiento de personas dentro y fuera del área geográfica en cuestión; en otras palabras, migración, que se divide en inmigración y emigración.
Empecemos con la primera cosa que necesita saber para construir un diagrama de población: la tasa de natalidad. Cada año nace cierto número de niños. La tasa de natalidad es el número medio de niños que tiene una mujer a lo largo de su vida. Esta tasa difiere de país en país dependiendo de un número de factores como cultura, situación económica, educación y costumbres. En alemania la tasa es de 1.3 hijos por mujer.
Unos países tienen una actitud "pro-natalidad" mayor que otros, los hijos pueden ser vistos en parte como una forma de seguro para cuando seamos viejos. En nuestro caso, la tasa de natalidad es un punto de partida para el programa, que se puede establecer entre 0 y 10 hijos por mujer. Es decir, podemos ajustar la tasa de natalidad en el programa para ajustarnos a distintas situaciones.
El número de niños nacidos no depende sólo de la tasa de natalidad, sino también del número de mujeres en edad de tener hijos. En el modelo, el número de mujeres en edad de tener hijos (para el programa, las edades entre 15 y 45) simplemente se suma y se multiplica por la tasa de natalidad. Para calcular el número de niños nacidos por año, este número se divide entre 45-15=30. Esto se basa en la suposición de que las mujeres, en media, tendrán a lo largo de su vida el número de hijos dado por la tasa de natalidad. Alguno se preguntará cómo se calcula realmente la tasa de natalidad ya que, después de todo, una mujer puede tener 7 hijos mientras que otra puede no tener ninguno. Esta es una cuestión estadística y se explica en la literatura especializada. En nuestro programa, estamos menos preocupados por la exactitud estadística y más por la posibilidad de la experimentación - por ejemplo, sobre la cuestión de qué ocurriría si se pusiese de moda en Alemania tener más de tres hijos por familia.
Claro que igual que nacen niños, también hay personas que mueren. La tasa de mortalidad es similar a la tasa de natalidad, salvo que se aplica a toda la población y no solo a las mujeres. (Por supuesto, los hombres también juegan un papel en la tasa de natalidad, pero este no es el lugar para discutirlo ;-)). Evidentemente la edad del invididuo es un factor principal en la tasa de mortalidad; estadísticamente las personas ancianas tienen más probabilidades de morir que las personas jóvenes. En Alemania existe una tabla oficial de tasa de mortalidad, que utilizan las compañías de seguros para calcular las primas de los seguros de vida. Nuestro programa utiliza los datos de esta tabla de tasa de mortalidad. Habrá que modificar estos datos para otros países.
En los países industrializados, la tasa debería basarse solo en la edad y no en factores adicionales como la clase social. Sin embargo, como me ha explicado un amigo mexicano, esto no se puede aplicar a todo el mundo. En nuestro programa, la tasa de mortalidad solo tiene en cuenta la edad, por lo que si alguien quiere añadir los factores sociales tendrá que ampliar el programa. ¿Quizás alguien quiera hacerlo?
Y por último habría que tener en cuenta la migración. Desde luego, los procesos migratorios siempre han jugado un importante papel. Por ejemplo, en siglos pasados, la población rural tendía a migrar a las ciudades. Esto no representaba un problema serio, en la medida que la alta tasa de natalidad cancelaba los efectos de la pérdida de población. Hoy en día los procesos migratorios son diferentes. Sin embargo, la despoblación rural todavía es un fenómeno significativo en la Alemania moderna, que implica el creciente aislamiento de algunas regiones.
El proceso completo es un autocatalítico que se ve reforzado por la degradación social y cultural. No vale de mucho tener facilidades para los niños en una zona en la que viven muy pocos niños. Al mismo tiempo, pocos querrán irse a una zona donde no haya facilidades para los niños. Pasa lo mismo con las facilidades culturales. Sin entrar mucho en los detalles, debería quedar claro que la migración puede tener muchas y variadas causas. Lo más importante para los propósitos del programa es que la estructura de edad de las personas que dejan una zona es normalmente diferente de las personas que llegan a esa zona. Para reflejarlo en el programa, se puede adaptar el campo "Distribution" en el código fuente "./demogra/demogra1.cpp" a nuestros propósitos. Esto no debería ser necesario en los experimentos iniciales.
Los campos "Immigration" y "Emigration" son para introducir esos datos. Esos campos toman valores absolutos. Luego, si 10000 personas al año se mueven a una zona, introduciremos 10,000 en el campo Immigration.
Por último (pero no menos importante), todos envejecemos un año cada año. Para tenerlo en cuenta, el ciclo de años hace que alguien que tuviera 40 años pase a tener 41. El campo "Step" nos permite avanzar varios años cada vez - por ejemplo, si especificamos 10, el modelo mostrará el desarrollo sobre un período de 10 años en un paso.
Echemos un vistazo a la interfaz de usuario del programa:
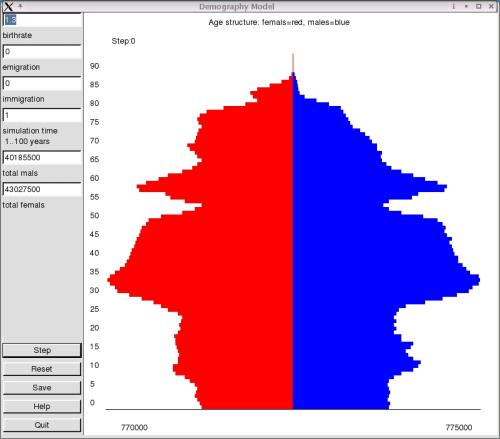
Los campos de entrada descritos anteriormente están en la parte izquierda de la pantalla. El número total de hombres y mujeres aparece en el campo correspondiente en esta parte de la pantalla después de cada paso. Estos campos son sólo de salida. De forma similar, todo el área gráfica está dedicada a la visualización. Los botones en la parte inferior izquierda de la pantalla sirven para controlar la simulación. El botón "Step" avanza un paso en la simulación. "Reset" lo reajusta todo a su estado inicial. El estado actual del modelo se puede guardar en el fichero "simulation.dat". Este fichero contiene el número de hombres y mujeres de cierta edad según refleja el modelo en el momento de guardarlo. Es posible llevar a cabo un análisis separado con este fichero. Los botones "Help" y "Quit" son autoexplicativos.
La parte inferior del gráfico muestra el máximo número de hombres y mujeres en todos los grupos de edad como un valor guía. Téngase en cuenta que el tamaño de las barras depende de esta figura máxima. Puede que no sea la mejor solución, pero todavía no he encontrado una alternativa. ¿A alguien se le ocurre algo?
Por otro lado, la simulación debería explicarse por sí misma. Si la entrada es extrema en un lado u otro - por ejemplo, si el número de emigrantes es muy alto - aparecerán huecos en pirámide de edad. Este tipo de resultados es improbable en la práctica, por lo que la entrada tendrá que ser apropiada. Por otro lado, ¿fenómenos patológicos, como el SIDA, podrían producir un efecto como éste en la realidad? ¿Podría ocurrir que en una zona cierto grupo de edad fuera diezmado por el SIDA, y el resto de la población fuera dejando la zona desierta?
El programa tiene licencia GLP. Para Qt se aplica la licencia TrollTech.
La instalación es muy sencilla. Lo primero es descargrse el modelo demográfico (véanse las referencias). Use tar -zxvf demographie-0.2.tar.gz para desempaquetar el fichero "demographie-0.2.tar.gz". La instalación se lanza desde el directorio recién creado mediante make o un previo qmake. Los prerequisitos son QT3 y gcc. El programa se ha probado satisfactoriamente en SuSE 8.0 y SuSE 8.1, y también debería funcionar con otras distribuciones.
Para arrancar el programa, ponga "./demographie" en la línea de comandos. Asegúrese de que "demo.csv" esté en el mismo directorio. Este fichero contien los números de los años, las figuras para hombres y mujeres, y las tasas de mortalidad para hombres y mujeres, todo como valores separados por comas. Si quiere ajustar los datos para adaptarlos a una región particular, lo tiene que hacer en este fichero. En nuestro ejemplo, un periódico fue la fuente de las figuras para Alemania. Puede que no sea completamente preciso, pero es adecuado para nuestros propósitos de experimentar.
El programa forma parte de un sistema de simulación regional. El sistema se ha diseñado para responder preguntas como ¿cómo evolucionará la población de una región geográfica bien definida (el área rural del norte de Berlín)? En particular, el sistema examinaba la llegada de familias jóvenes a zonas cercanas a Berlín y la partida de personas jóvenes al Western Bundesländer. Los resultados mostraban grandes diferencias de región en región. Hay algunas zonas donde la población está creciendo y otras cuya población decrece. Algunas zonas, especialmente las más remotas geográficamente, se están volviendo más y más escasamente pobladas. Un efecto notable en esto es el proceso autocatalítico referido anteriormente.
Tenemos que ser cuidados con este tipo de predicciones, ya que no se han incluido todos los datos relevantes en este proceso. Por ejemplo, el fenómeno del teletrabajo se traduce en que la distancia a Berlín ya no será tan importante como parece. Los programas para promover zonas particulares como buenos lugares industriales también pueden crear escenarios diferentes. En consecuencia, los modelos simplemente representan una continuación del estado actual y solo sirven de forma orientativa.
Si queremos aplicar el programa a otras áreas del mundo, tendremos que considerar también otros procesos. Podría ser interesante usar el programa para examinar un área completamente distinto, como por ejemplo las regiones rurales de México. Aquí hacen falta montones de nuevas ideas. ¿Quizás alguien querría ver esto en mayor detalle, o adaptar el modelo a otras regiones? Me alegraría recibir comentarios en este aspecto.
Querría enviar un sincero agradecimiento a la comunidad Linux, que ha desarrollado tan fantástico sistema. También doy las gracias a la empresa Troll Tech por la brillante QT y por hacerla disponible para Linux. Y por supuesto un agradecimiento especial a la FSF por tantas herramientas, especialmente gcc, sin las que el trabajo presentado aquí no habría sido posible.
Happy hacking!
|
|
Contactar con el equipo de LinuFocus
© Ralf Wieland, FDL LinuxFocus.org |
Información sobre la traducción:
|
2003-03-14, generated by lfparser version 2.34