
original in fr: Vincent Renardias
fr to en Georges Tarbouriech
en to ru Воронин Леонид
Пользователь GNU/Linux с 1993, Винсент Ренардиас (Vincent Renardias) начал увлекаться его разработкой в 1996: Разработчик Debian, Французский переводчик программы GIMP и рабочего стола GNOME, основатель группы пользователей Linux User Group в Марселе (PLUG)... Теперь, управляющий компании R&D EFB2, он продолжает содействие GNU/Linux.
Данная статья впервые была опубликована в специальном выпуске Linux Magazine France, сосредоточенном на безопасности. Редактор, авторы и переводчики любезно позволили LinuxFocus публиковать все статьи из этого специального выпуска. Соответственно LinuxFocus передаст их вам сразу же после перевода на английский. Спасибо всем, кто вовлечен в эту работу. Данное резюме будет воспроизведено во всех статьях, имеющих то же происхождение.
Один из хороших путей предотвратить попытки вторжения - это фильтрация, которая бесполезна в сети.
Эта задача обычно приписана компьютеру, используемому в качестве брандмауэра (firewall).
В данной статье мы предоставим необходимую базу для осуществления и конфигурирования такой системы.
![[Illustration]](../../common/images/article289/illustration289.jpg)
Механизм фильтрации может быть рассмотрен как сеть, которая будет задерживать
некоторые нежелательные пакеты. Наиболее важно найти правильный размер петли (ячейки сети)
и правильное место для установки сети.
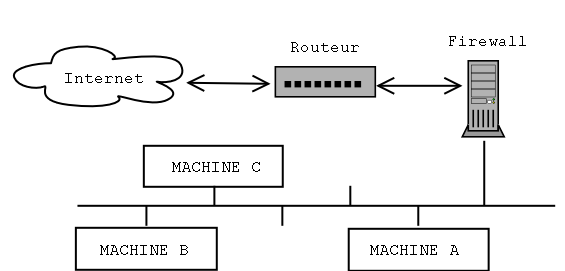
Чтобы фильтрующий механизм был в состоянии осуществлять фильтрацию пакетов должным образом,
он должен быть физически размещен между защищаемой сетью и "внешним миром".
Практически это осуществляется при помощи компьютера, имеющего два сетевых интерфейса
(обычно Ethernet), один из которых подключен к внутренней сети, а другой - к
маршрутизатору, через который осуществляется доступ к внешней сети.
Таким образом, коммуникации должны будут идти через брандмауэр, который
будет или не будет блокировать их в зависимости от их содержания.
Компьютер, осуществляющий фильтрацию, может быть настроен тремя разными путями:
- "Простой" шлюз: это наиболее часто используемая конфигурация. Компьютер
используется как шлюз между двумя сетями или подсетями.
Компьютеры локальной сети должны быть настроены на использование брандмауэра
вместо маршрутизатора в качестве маршрута по умолчанию (основного шлюза).
- Шлюз "ARP-Прокси": предыдущая конфигурация подразумевает деление сети на две
подсети, которые приводят к потере половины доступных для сети IP адресов.
Это немного раздражает. Например, из 16-ти адресной подсети (с 28 битной маской подсети),
только 14 доступны, с тех пор как используются адрес сети и широковещательный адрес.
Добавляя ещё один бит в маску подсети, мы уменьшаем доступные адреса с 14 до 6
(8 адресов за вычетом адреса сети и широковещательного адреса).
Когда вы не можете допустить потери половины доступных IP-адресов, вы можете использовать
данное решение, которое объясняется далее в этой статье.
Кроме того, данное решение не требует каких-либо изменений в настройке сети
ни на маршрутизаторе, ни на защищаемых компьютерах.
- Мост Ethernet: устанавливая шлюз Ethernet (не IP
шлюз), делают механизм фильтрации невидимым с других компьютеров.
Такая конфигурация может быть выполнена без назначения IP адресов Ethernet-интерфейсам.
В таком случае, компьютеры невозможно обнаружить при помощи ping, traceroute и т.п.
Следует заметить, что выполнение фильтрации пакетов в такой конфигурации требует
ядра версии 2.2.x, а перенос данной функции на ядра версии 2.4.x пока не закончен.
Теперь, когда мы знаем где установить наш фильтр, мы должны определить, что
он должен будет блокировать или что он должен будет пропускать.
Есть два пути настройки такого фильтра:
- Первый, хороший: задерживаем все пакеты, кроме тех, которые соответствуют правилам.
- Второй, плохой: (но к сожалению, часто используемый) явно запрещенные
пакеты задерживаются, а все остальные пропускаются.
Это просто объясняется: В первом случае, забывание (нарушение) правил приводят к
нарушению работы службы или полной утере работоспособности.
Обычно это быстро выявляется и проидводится добавление правил, достаточных
для возобновления работы.
Во втором случае, забывание (нарушение) правил создает потенциальную уязвимость,
которую часто очень сложно выявить... если можно вообще.
Наиболее часто используемое программное обеспечение для фильтрации пакетов в Linux - это Netfilter; эта приятная замена 'ipchains', используемой в Linux с ядром 2.2. Netfilter сделан из двух частей: поддержка ядра, которая должна быть скомпилирована в вашем ядре и команды 'iptables' которые должны быть доступны в вашей системе.
Комментированный пример лучше, чем длинная речь. Потом мы опишем, как установить и настроить механизм фильтрации. Для начала, компьютер будет сконфигурирован как шлюз, использующий ARP-прокси для ограничения числа IP-адресов, а потом мы настроим систему фильтрации.
Автор отдает предпочтение дистрибутиву Debian для настройки такой системы, но аналогично может быть настроен любой другой дистрибутив.
Во-первых, проверим, что ваше ядро поддерживает Netfilter. Если это так, то загрузочная запись должна содержать:
ip_conntrack (4095 buckets, 32760 max)
ip_tables: (c)2000 Netfilter core team
Иначе, вам придется перекомпилировать ядро после активизации поддержки Netfilter. Соответствующие опции могут быть найдены в подменю "Network Packet Filtering" меню "Networking Options". Выберите необходимые опции в секции "Netfilter Configuration". Если вы сомневаетесь, можете выбрать все опции, кроме того, лучше включить Netfilter в ядро и не использовать модули. Если по каким-то причинам один из модулей Netfilter был пропущен или не загружен, фильтрация работать не будет и мы лучше не будем говорить о риске, который подразумевается в данном случае.
Вы так же можете установить пакет 'iproute2' (последнее не обязательно, но
наш пример будет использовать данный пакет, так как данный пакет позволяет
сделать конфигурационный скрипт (сценарий) проще). В дистрибутиве Debian,
для установки пакета 'iproute2' достаточно набрать команду
'apt-get install iproute'.
В других дистрибутивах, найдите соответствующие пакеты. Установить их можно
обычным путем или из исходных кодов, которые можно загрузить со следующего адреса:
ftp://ftp.inr.ac.ru/ip-routing/
Теперь должны быть сконфигурированы две Ethernet карты. Мы должны обратить ваше
внимание на то, что ядро Linux, когда производит автоопределение оборудования,
останавливает поиск сетевых карт как только найдет первую. Соответственно,
определится только первая.
Легкое решение этой проблемы состоит в добавлении
следующей строки в файл lilo.conf:
append="ether=0,0,eth1"
Теперь мы должны настроить Ethernet-интерфейсы.
Выбранный нами метод позволяет использовать один и тот же IP-адрес для
обоих плат, сохраняя, таким образом, один адрес.
Допустим, что у нас есть подсеть 10.1.2.96/28,
адреса которой начинаются с 10.1.2.96 по 10.1.2.111 включительно.
Маршрутизатор будет иметь адрес 10.1.2.97, а наш компьютер для
фильтрации - 10.1.2.98. Интерфейс eth0 будет подключен к
маршрутизатору через соединительный кабель RJ-45, если
обе карты соединены напрямую, без использования хаба (hub) или свитча
(switch); Интерфейс eth1 будет подключен к хабу/свитчу, а оттуда
- к компьютерам локальной сети.
Соответственно, оба интерфейса будут сконфигурированы со следующими параметрами:
address : 10.1.2.98 netmask : 255.255.255.240 network : 10.1.2.96 broadcast: 10.1.2.111 gateway : 10.1.2.97
Далее используем следующий скрипт (сценарий), который должен запускаться после
начальной конфигурации сетевых карт для завершения установки.
net.vars: configuration variables PREFIX=10.1.2 DMZ_ADDR=$PREFIX.96/28 # Interface definitions BAD_IFACE=eth0 DMZ_IFACE=eth1 ROUTER=$PREFIX.97 net-config.sh: network configuration script #!/bin/sh # Comment out the next line to display the commands at execution time # set -x # We read the variables defined in the previous file source /etc/init.d/net.vars # We remove the present routes from the local network ip route del $PREFIX.96/28 dev $BAD_IFACE ip route del $PREFIX.96/28 dev $DMZ_IFACE # We define that the local network can be reached through eth1 # and the router through eth0. ip route add $ROUTER dev $BAD_IFACE ip route add $PREFIX.96/28 dev $DMZ_IFACE # We activate Proxy-ARP for both interfaces echo 1 > /proc/sys/net/ipv4/conf/eth0/proxy_arp echo 1 > /proc/sys/net/ipv4/conf/eth1/proxy_arp # We activate the IP forwarding to allow the packets coming to one card # to be routed to the other one. echo 1 > /proc/sys/net/ipv4/ip_forward
Теперь, давайте вернемся к требуемому механизму ARP-прокси
для нашей конфигурации.
Для того чтобы один компьютер мог "общаться" с другим в той же
сети, ему необходимо знать Ethernet адрес (или MAC адрес или аппаратный
адрес), сообщаемый его IP-адресу.
Тогда компьютер-источник отправляет запрос: "Какой MAC-адрес интерфейса,
имеющего IP-адрес 1.2.3.4 ?" и компьютер-приемник должен ответить.
Вот пример такого "общения", обнаруженного при помощи tcpdump:
- Запрос: компьютер 172.16.6.72 спрашивает MAC-адрес, передаваемый IP-адресу 172.16.6.10.
19:46:15.702516 arp who-has 172.16.6.10 tell
172.16.6.72
- Ответ: компьютер 172.16.6.10 предоставляет свой номер сетевой карты.
19:46:15.702747 arp reply 172.16.6.10 is-at 0:a0:4b:7:43:71
Это приводит нас к следующему короткому объяснению: ARP-запросы осуществляются при помощи широковещательных запросов, ограниченных только одной физической сетью. Таким образом, запрос от защищенного компьютера на нахождение MAC-адреса маршрутизатора, должен быть блокирован фильтрующим компьютером. Активация возможностей ARP-прокси позволяет решить эту проблему, так как он будет передавать ARP-запросы.
На данном уровне, вы должны иметь работающую сеть с компьютером, управляющим всем трафиком между локальной и внешней сетью.
Теперь, мы должны настроить фильтрацию используя Netfilter.
Netfilter позволяет действовать непосредственно на поток пакетов.
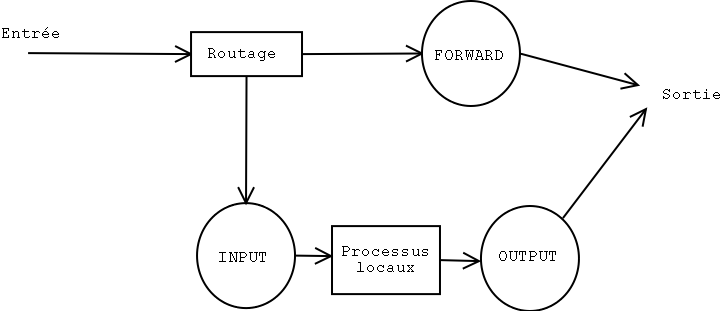
В простейшей конфигурации, пакеты управляются тремя цепочками правил:
- INPUT: для пакетов, входящих через интерфейс,
- FORWARD: для всех пакетов, передающихся от одного интерфейса к другому,
- OUTPUT: для пакетов, выходящих через интерфейс.
Команда 'iptables' позволяет добавлять, изменять и удалять правила в
каждой из этих цепочек для изменения поведения фильтрации.
Кроме того, каждая цепочка имеет политику по умолчанию, которая определяет
действия в случае, когда пакет не соответствует ни одному правилу в цепочке.
Четыре наиболее распространенных правила - это:
- ACCEPT: пакету позволено проходить,
- REJECT: пакет отклоняется и посылается пакет, связанный с ошибкой
(ICMP Port Unreachable, TCP RESET, в зависимости от ситуации),
- LOG: Примечание пакета пишется в системный журнал,
- DROP: Пакет игнорируется и ответ не посылается.
Вот главные опции iptables, позволяющие управлять цепочками. Мы детализируем их позже:
-N: создает новую цепочку.
-X: удаляет пустую цепочку.
-P: изменяет политику цепочки по умолчанию.
-L: выводит список правил в цепочке.
-F: сбрасывает все правила в цепочке.
-Z: очищает байты и счетчики пакетов, прошедших через цепочку.
Для изменения цепочки доступны следующие команды:
-A: добавляет правило в конец цепочки.
-I: вставляет новое правило в заданную позицию в цепочке.
-R: заменяет заданное правило в цепочке.
-D: удаление правила в цепочке, используя либо номер правила, либо его описания.
Давайте рассмотрим маленький практический пример: мы заблокируем ping-ответы
(это тип ICMP-пакетов 'echo-reply'), идущие от заданного компьютера.
Сначала удостоверимся, что заданный компьютер "пингуется" (т.е. отвечает на команду ping):
# ping -c 1 172.16.6.74 PING 172.16.6.74 (172.16.6.74): 56 data bytes 64 bytes from 172.16.6.74: icmp_seq=0 ttl=255 time=0.6 ms --- 172.16.6.74 ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 0.6/0.6/0.6 msТеперь, добавим правило (которое прервет ICMP-ответ) в INPUT-цепочку ('-p icmp --icmp-type echo-reply') для пакетов, идущих с компьютера 172.16.6.74 ('-s 172.16.6.74'). Эти пакеты будут проигнорированы ('-j DROP').
# iptables -A INPUT -s 172.16.6.74 -p icmp --icmp-type echo-reply -j DROP
Теперь, давайте снова "пинганем" этот компьютер:
# ping -c 3 172.16.6.74 PING 172.16.6.74 (172.16.6.74): 56 data bytes --- 172.16.6.74 ping statistics --- 3 packets transmitted, 0 packets received, 100% packet loss
Как мы и могли ожидать, пакеты не прошли. Мы можем проверить, что три пакета были заблокированы (3 пакета или 252 байта):
# iptables -L INPUT -v Chain INPUT (policy ACCEPT 604K packets, 482M bytes) pkts bytes target prot opt in out source destination 3 252 DROP icmp -- any any 172.16.6.74 anywhere
Чтобы вернуть все как было, нам надо только удалить первое правило из цепочки INPUT:
# iptables -D INPUT 1
Теперь, PING заработает снова:
# ping -c 1 172.16.6.74 PING 172.16.6.74 (172.16.6.74): 56 data bytes 64 bytes from 172.16.6.74: icmp_seq=0 ttl=255 time=0.6 ms --- 172.16.6.74 ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 0.6/0.6/0.6 ms #
Работает!
Вы можете добавить другие цепочки к трем изначально существующим (которые вы не сможете удалить в любом случае) и сделать часть трафика проходящим через них. Например, может быть полезным избегать дублирования правил в различных цепочках.
Теперь, давайте настроим требуемые правила для минимального брандмауэра.
Он будет позволять ssh, службу доменных имен (DNS), службы http и smtp и
ничего больше.
Для упрощения, команды настройки записаны в сценарий оболочки (скрипт),
чтоб сделать конфигурацию проще. Сценарий начнет очищать текущую конфигурацию
перед установкой новой. Эта маленькая уловка позволяет выполняться скрипту при
активной конфигурации без риска дублирования правил.
rc.firewall #!/bin/sh # Flushing out the rules iptables -F iptables -F INPUT iptables -F OUTPUT iptables -F FORWARD # The chain is built according to the direction. # bad = eth0 (outside) # dmz = eth1 (inside) iptables -X bad-dmz iptables -N bad-dmz iptables -X dmz-bad iptables -N dmz-bad iptables -X icmp-acc iptables -N icmp-acc iptables -X log-and-drop iptables -N log-and-drop # Specific chain used for logging packets before blocking them iptables -A log-and-drop -j LOG --log-prefix "drop " iptables -A log-and-drop -j DROP # The packets having the TCP flags activated are dropped # and so for the ones with no flag at all (often used with Nmap scans) iptables -A FORWARD -p tcp --tcp-flags ALL ALL -j log-and-drop iptables -A FORWARD -p tcp --tcp-flags ALL NONE -j log-and-drop # The packets coming from reserved addresses classes are dropped # and so for multicast iptables -A FORWARD -i eth+ -s 224.0.0.0/4 -j log-and-drop iptables -A FORWARD -i eth+ -s 192.168.0.0/16 -j log-and-drop iptables -A FORWARD -i eth+ -s 172.16.0.0/12 -j log-and-drop iptables -A FORWARD -i eth+ -s 10.0.0.0/8 -j log-and-drop # The packets belonging to an already established connexion are accepted iptables -A FORWARD -m state --state INVALID -j log-and-drop iptables -A FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT # The corresponding chain is sent according to the packet origin iptables -A FORWARD -s $DMZ_ADDR -i $DMZ_IFACE -o $BAD_IFACE -j dmz-bad iptables -A FORWARD -o $DMZ_IFACE -j bad-dmz # All the rest is ignored iptables -A FORWARD -j log-and-drop # Accepted ICMPs iptables -A icmp-acc -p icmp --icmp-type destination-unreachable -j ACCEPT iptables -A icmp-acc -p icmp --icmp-type source-quench -j ACCEPT iptables -A icmp-acc -p icmp --icmp-type time-exceeded -j ACCEPT iptables -A icmp-acc -p icmp --icmp-type echo-request -j ACCEPT iptables -A icmp-acc -p icmp --icmp-type echo-reply -j ACCEPT iptables -A icmp-acc -j log-and-drop # Outside -> Inside chain # mail, DNS, http(s) and SSH are accepted iptables -A bad-dmz -p tcp --dport smtp -j ACCEPT iptables -A bad-dmz -p udp --dport domain -j ACCEPT iptables -A bad-dmz -p tcp --dport domain -j ACCEPT iptables -A bad-dmz -p tcp --dport www -j ACCEPT iptables -A bad-dmz -p tcp --dport https -j ACCEPT iptables -A bad-dmz -p tcp --dport ssh -j ACCEPT iptables -A bad-dmz -p icmp -j icmp-acc iptables -A bad-dmz -j log-and-drop # Inside -> Outside chain # mail, DNS, http(s) and telnet are accepted iptables -A dmz-bad -p tcp --dport smtp -j ACCEPT iptables -A dmz-bad -p tcp --sport smtp -j ACCEPT iptables -A dmz-bad -p udp --dport domain -j ACCEPT iptables -A dmz-bad -p tcp --dport domain -j ACCEPT iptables -A dmz-bad -p tcp --dport www -j ACCEPT iptables -A dmz-bad -p tcp --dport https -j ACCEPT iptables -A dmz-bad -p tcp --dport telnet -j ACCEPT iptables -A dmz-bad -p icmp -j icmp-acc iptables -A dmz-bad -j log-and-drop # Chains for the machine itself iptables -N bad-if iptables -N dmz-if iptables -A INPUT -i $BAD_IFACE -j bad-if iptables -A INPUT -i $DMZ_IFACE -j dmz-if # External interface # SSH only accepted on this machine iptables -A bad-if -p icmp -j icmp-acc iptables -A bad-if -p tcp --dport ssh -j ACCEPT iptables -A bad-if -p tcp --sport ssh -j ACCEPT ipchains -A bad-if -j log-and-drop # Internal interface iptables -A dmz-if -p icmp -j icmp-acc iptables -A dmz-if -j ACCEPT
Несколько слов о качестве обслуживания. Linux может модифицировать поле ToS ("тип сервиса") и изменять его значения, чтобы дать пакетам различные приоритеты. Например, следующая команда изменяет исходящие SSH пакеты для улучшения отклика соединения.
iptables -A OUTPUT -t mangle -p tcp --dport ssh -j TOS --set-tos Minimize-Delay
Тем же путем, для FTP соединений, вы можете использовать опцию '--set-tos Maximize-Throughput' для улучшения скорости передачи.
Вот и всё. Теперь, вы знаете основы настройки системы фильтрации пакетов.
Однако, имейте ввиду, что брандмауэр - не панацея, когда беспокоит безопасность.
Это всего лишь ещё одна предосторожность. Установка брандмауэра не освобождает
вас от использования хороших ("сильных") паролей, самых последних патчей по
безопасности, систем обнаружения вторжений и т.д.