
original in en Brian Hone
en to pl Mariusz Kozģowski
Brian Hone jest administratorem i programistą w korporacji E Ink. W wolnych chwilach ŋegluje na bardzo zimnych wodach i wisi na skaģkach .

Mogę przytoczyæ dģugą listę powodów, dla których archiwizazja danych to koszmar administratora. Jeķli jesteķ administratorem, prawdopodobnie nie muszę tego robiæ. Niektóre z powodów to: drogi sprzęt, który wysiada częķciej niŋ pracuje, drogie oprogramowanie, którego zarządzanie to koszmar i dģugie godziny spędzone na odzyskiwaniu odpowiednich wersji plików. Ŋeby jeszcze pogorszyæ sprawę zwykle korporacja przykģada bardzo maģo wagi do kopii zapasowych, aŋ do tego nieuniknionego dnia, gdy są one naprawdę potrzebne. Jeķli zarchiwizowaģeķ/odzyskaģeķ dane odbyģeķ taką rozmowę:
User: "Zgubiģem plik. Chcę abyķ odzyskaģ go natychmiast."
SysAdmin: "Ok, jak się nazywaģ?"
User: "Nie wiem, chyba miaģ 'e' w nazwie."
SysAdmin: "Ok, więc w jakim byģ katalogu?"
User: "Nie wiem, mógģ byæ w jednym z tych trzech..."
SysAdmin: "*westchnięcie* Kiedy ostatnio go uŋywaģeķ?"
User: "Hmmm... To chyba byģ czwartek w lutym czy kwietniu. W czym problem?
Myķlaģem, ŋe macie kopie zapasowe w takich sytuacjach."
Rsync to bardzo dobra implementacja maģego pięknego algorytmu. Jego podstawowa zaleta to moŋliwoķæ efektywnego mirrorowania sysetmu plików. Uŋywając rsync prostym jest stworzenie systemu, który będzie przechowywaģ ķwieŋą kopię obserwowanego systemu plików uŋywając róŋnych protokoģów sieciowych jak nfs, smb czy ssh. Drugą waŋną wģaķciwoķcią rsync jest moŋliwoķæ archiwizacji starych kopii plików, które zostaģy zmodyfikowane lub usunięte. Istnieje zdecydowanie zbyt wiele wģaķciwoķci aby je rozwaŋaæ w tym artykule. Gorąco polecam lekturę rsync.samba.org.
Po krótce system ten skģada się z taniej maszyny opartej na Linux'ie z masą tanich dysków i maģym skryptem powģoki zwanym rsync. [Fig 1] Gdy archiwizujemy dane mówimy rsync aby stworzyģ katalog o nazwie 'YY-DD-MM' jako miejsce do przechowywania zmian. Następnie rsync sprawdza czy na serwerach które archiwizujemy zaszģy jakieķ zmiany. Jeķli jakiķ plik ulegģ zmianie stara wersja jest kopiowana do wczesniej opisanego katalogu, a požniej nadpisuje plik w gģównym katalogu z archwizowanymi danymi. [Fig 2]
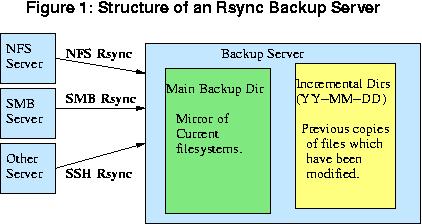
Ogólnie dzienne zmiany stanowią maģy procent caģego systemu plików. Wg moich testów wartoķæ ta zwykle wacha się w przedziale 0.5% do 1%. Dlatego teŋ z zestawem dysków o rozmiarze dwukrotnie większym od naszych archiwizowanych systemów moŋesz przechowaæ okoģo 50-100 dni zmian. Gdy dysk staje się peģny po prostu podepnij nowy zestaw dysków, a stare odepnij. W praktyce jest moŋliwe przechowanie ponad szeķciu miesięcy zmian na dysku. Wģaķciwie jeķli znajdziesz gdzieķ miejsce moŋesz skopiowaæ archiwizowane dane na inny serwer zanim zmienisz dyski. W ten sposób moŋesz przechowaæ caģkiem duŋą liczbę katalogow zmian na dysku.
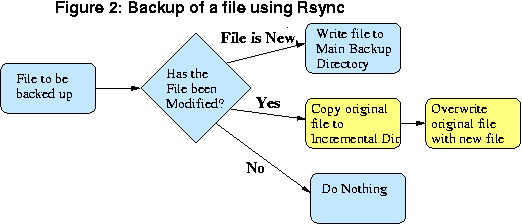
Wróæmy do powyŋszej, wyimaginowanej rozmowy. Wyobraž sobie teraz, ŋe zamiast nieporęcznego systemu opartego o taķmy masz system oparty o Linux'a z czekającymi na Ciebie danymi z ostatnich szeķciu miesięcy. Uŋywając Twojej ulubionej kombinacji locate/find/grep moŋesz znaležæ wszystkie pliki naleŋące do danego uŋytkownika zawierające 'e' z datą czwartek luty bądž kwiecieņ i zrzuciæ je do katalogu tego wlaķnie uŋytkownika. Problem w znalezieniu, która z wersji jest waķciwa to jeden z moich ulubionych rodzajów problemu: to nie mój problem.
Nstępnie wyobraž sobie nasz ulubiony scenariusz - caģkowita utrata danych. Powiedzmy, ŋe masz wielki serwer nfs/samba, który tracisz. Jeķli zarchiwizowaģeķ pliki konfiguracyjne samby moŋesz przywróciæ serwer jako chwilowo tylko do odczytu w parę minut. Chciaģbym zobaczyæ jak to robisz z taķmami.
| Archiwizacja na taķmie | Rsync | |
|---|---|---|
| Koszt | Bardzo duŋy | Maģy |
| Peģna archiwizacja | Szybko | Szybko |
| Archiwizacja zmian | Szybko | Szybko |
| Peģne odzyskiwanie systemu | Bardzo wolno, prawdopodownie wiele taķm | Szybko - wszystko jest na dysku |
| Przywracanie plików | Powoli, moŋe wiele taķm, często problem ze znalezieniem wģaķciwej wersji. | Bardzo szybko - wszystko jest na dysku, a na dodatek masz pod ręką narzędzia systemu UN*X jak: find, grep i locate |
| Caģkowita utrata danych | Jednyna moŋliwoķæ to peģne odzyskiwanie systemu | Moŋe zostaæ przywrócony jako serwer plików w parę minut |
Istnieje wiele kombinacji konfiguracji systemu archiwizacji. Wszystkie narzędzia są open-source, zawarte standardowo w dystrybucjach i bardzo elastyczne. Opiszemy tutaj jedną z wielu moŋliwoķci konfiguracji.
Podstawowa wersja tego skryptu pochodzi ze strony rsync. Jest to naprawdę jedno polecenie:
rsync --force --ignore-errors --delete --delete-excluded --exclude-from=exclude_file --backup --backup-dir=`date +%Y-%m-%d` -av
Kluczowe opcje to:
Poniŋszy skrypt moŋe byæ odpalany co noc uŋwając linux'owego cron. Aby skrypt byģ uruchamiany o 23 co noc uŋyj polecenia "crontab -e", a potem wpisz to:
0 23 * * * /ķcieŋka/do/twojego/skryptu
Oto mój skrypt powģoki wiąŋący to wszystko w caģoķæ. Znowu istnieje wiele sposobów na zrealizowanie tego. Jest to tylko jedna z implementacji.
#!/bin/sh
#########################################################
# Script to do incremental rsync backups
# Adapted from script found on the rsync.samba.org
# Brian Hone 3/24/2002
# This script is freely distributed under the GPL
#########################################################
##################################
# Configure These Options
##################################
###################################
# mail address for status updates
# - This is used to email you a status report
###################################
MAILADDR=your_mail_address_here
###################################
# HOSTNAME
# - This is also used for reporting
###################################
HOSTNAME=your_hostname_here
###################################
# directory to backup
# - This is the path to the directory you want to archive
###################################
BACKUPDIR=directory_you_want_to_backup
###################################
# excludes file - contains one wildcard pattern per line of files to exclude
# - This is a rsync exclude file. See the rsync man page and/or the
# example_exclude_file
###################################
EXCLUDES=example_exclude_file
###################################
# root directory to for backup stuff
###################################
ARCHIVEROOT=directory_to_backup_to
#########################################
# From here on out, you probably don't #
# want to change anything unless you #
# know what you're doing. #
#########################################
# directory which holds our current datastore
CURRENT=main
# directory which we save incremental changes to
INCREMENTDIR=`date +%Y-%m-%d`
# options to pass to rsync
OPTIONS="--force --ignore-errors --delete --delete-excluded \
--exclude-from=$EXCLUDES --backup --backup-dir=$ARCHIVEROOT/$INCREMENTDIR -av"
export PATH=$PATH:/bin:/usr/bin:/usr/local/bin
# make sure our backup tree exists
install -d $ARCHIVEROOT/$CURRENT
# our actual rsyncing function
do_rsync()
{
rsync $OPTIONS $BACKUPDIR $ARCHIVEROOT/$CURRENT
}
# our post rsync accounting function
do_accounting()
{
echo "Backup Accounting for Day $INCREMENTDIR on $HOSTNAME:">/tmp/rsync_script_tmpfile
echo >> /tmp/rsync_script_tmpfile
echo "################################################">>/tmp/rsync_script_tmpfile
du -s $ARCHIVEROOT/* >> /tmp/rsync_script_tmpfile
echo "Mail $MAILADDR -s $HOSTNAME Backup Report < /tmp/rsync_script_tmpfile"
Mail $MAILADDR -s $HOSTNAME Backup Report < /tmp/rsync_script_tmpfile
echo "rm /tmp/rsync_script_tmpfile"
rm /tmp/rsync_script_tmpfile
}
# some error handling and/or run our backup and accounting
if [ -f $EXCLUDES ]; then
if [ -d $BACKUPDIR ]; then
# now the actual transfer
do_rsync && do_accounting
else
echo "cant find $BACKUPDIR"; exit
fi
else
echo "cant find $EXCLUDES"; exit
fi